

2023年6月5日
Kubernetes
Kubernetesデプロイの検証が簡単に
Harness(最新の継続的デリバリープラットフォーム)は、DevOpsプロフェッショナルが任意の監視ツールを使用してデプロイメントを検証できるように、Continuous Verificationと呼ばれる機能を導入しました。
 現代のソフトウェア企業は、自動化と開発者の効率化に重点を置いています。DevOpsアプローチがソフトウェア開発チームとデリバリーチームに翼を与えていることは間違いありませんが、最近ではセキュリティー、ロギング、監視の重要性がはるかに高まっています。アプリケーションとサービスを本番環境にデプロイした後は、それらを監視することを強くお勧めします。異常が検出された場合は、サービスや顧客に影響を与える前に、その場で修正しましょう。しかし、サービスやアプリケーションを継続的に監視するにはどうすればよいでしょうか。ロギングとモニタリングを理解している経験豊富なエキスパートが必要であり、サードパーティー製ツ�ールは高価でセットアップに時間がかかります。
現代のソフトウェア企業は、自動化と開発者の効率化に重点を置いています。DevOpsアプローチがソフトウェア開発チームとデリバリーチームに翼を与えていることは間違いありませんが、最近ではセキュリティー、ロギング、監視の重要性がはるかに高まっています。アプリケーションとサービスを本番環境にデプロイした後は、それらを監視することを強くお勧めします。異常が検出された場合は、サービスや顧客に影響を与える前に、その場で修正しましょう。しかし、サービスやアプリケーションを継続的に監視するにはどうすればよいでしょうか。ロギングとモニタリングを理解している経験豊富なエキスパートが必要であり、サードパーティー製ツ�ールは高価でセットアップに時間がかかります。
これらの問題点を念頭に、Harnessは、DevOpsプロフェッショナルが任意の監視ツールを使用して項目を検証できる新機能「Continuous Verification」をリリースしました。
ここではContinuous Verification(CV)について説明し、HarnessのContinuous Verification機能を使用してKubernetes項目を検証する方法を説明します。
Continuous Verificationとは
CVは、ソフトウェアデプロイの品質を継続的に監視および検証し、デプロイされたアプリケーションとサービスが期待通りに機能していることを確認するアプローチです。ソフトウェアシステムに加えられた変更が正常にデプロイされ、システムのパフォーマンスや機能に悪影響を与えないことを保証するプロセスです。ソフトウェアのデプロイの流れでは、CVには、Prometheus、AppDynamics、NewRelic、Splunk、Datadog、Dynatrace、CloudWatch、Elasticsearchなどの監視ツールを使用して、新しくデプロイされたアプリケーションまたはサービスが正しく動作していることを検証および確認することが含まれます。サービス/アプリは、いつでも期待通りに動作するよう常に監視されます。
CVには、アプリケーションのパフォーマンスとログの監視、エラーとバグのチェック、アプリケーションが全ての機能要件を満たしているこ��との確認が含まれます。CVはCDプロセスの重要な部分であり、ソフトウェア開発チームが新しいソフトウェアバージョンを迅速、頻繁、そして自信を持ってデリバリーできるようにすることを目的としています。項目の品質を継続的に検証することで、開発チームは問題を早期に発見して迅速に修正でき、アプリケーションは常にスムーズに実行されます。異常が検出された場合は、サービスのダウンタイムを回避するために、すぐに報告して修正する必要があります。
Harness Continuous Verification
Harness CVは、導入の品質とパフォーマンスを確保するのに役立つ強力なツールです。Harnessを使用すると、デプロイを検証するためのパイプラインを簡単にセットアップし、選択したさまざまな監視ツールを接続できます。パイプラインで検証ステップを設定すると、Harnessは教師なし機械学習を使用して、デプロイされたアプリケーションまたはサービスの異常を検出します。これらの異常に対してしきい値を設定でき、設定したしきい値を超えた場合、自動的にロールバックしてデプロイのリスクを回避できます。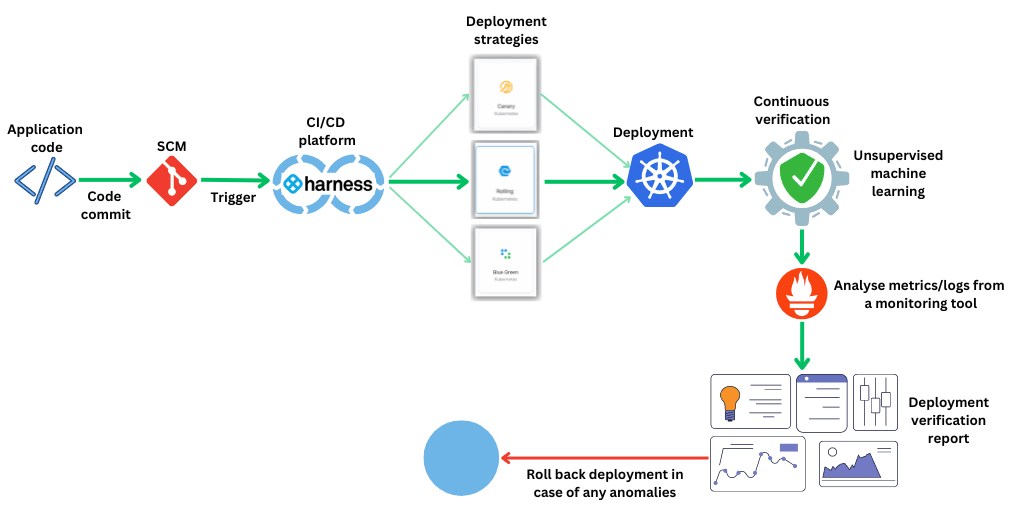 問題が検出された場合、チームはアラートを受け取り、デプロイのステータスに関する詳細なレポートを表示して、発生した問題を修正する措置を講じることができます。全体として、Harness CVは、デプロイの信頼性と品質を確保したい組織には不可欠な機能です。Harnessでは、運用環境および運用後の導入検証を実行して、導入が適切に行われ、監視されていることを確認できます。
問題が検出された場合、チームはアラートを受け取り、デプロイのステータスに関する詳細なレポートを表示して、発生した問題を修正する措置を講じることができます。全体として、Harness CVは、デプロイの信頼性と品質を確保したい組織には不可欠な機能です。Harnessでは、運用環境および運用後の導入検証を実行して、導入が適切に行われ、監視されていることを確認できます。
Prometheusを使用してHarness CDでのデプロイを検証するには、次の簡単な手順に従うことができます。
- アプリケーションのインストルメント:アプリケーションコード内のPrometheusクライアントライブラリーを使用して関連コンポーネントをインストルメントできます。これらのライブラリーは、Prometheusが収集するメトリクスを公開します。マニフェストファイルを通じてそれらを接続できます。
- Prometheusエンドポイントのセットアップ:項目からメトリクスを収集および保存するために、環境内でPrometheusがセットアップおよび実行されていることを確認します。
- Harnessの検証ステップのセットアップ:Harnessデプロイパイプラインに検証ステップを作成します。必要な段階で検証ステップをデプロイパ��イプラインに統合できます。この検証ステップでは、Prometheus統合を使用してPrometheusからメトリクスを取得し、期待値のチェックを実行する必要があります。
コネクター経由でHarnessにPrometheusを構成する:必要に応じて、PrometheusサーバーのURLや認証資格情報など、必要な接続の詳細を入力してください。このステップにより、Harnessはデータを取得するためにPrometheusにアクセスできるようになります。
クエリーによる検証基準の定義:検証するメトリクスを指定し、成功または失敗の基準を定義します。例えば、特定のメトリクス値が許容範囲内にあるか、特定のしきい値を満たしているかを検証できます。クエリー式に基づいてアサーションを構成し、値を比較し、返されたメトリクスの特定のパターンを確認できます。
- デプロイの実行と監視:Harness CDを通じて項目をトリガーし、パイプラインの検証ステップを監視します。HarnessはPrometheusからメトリクスを自動的に取得し、定義された基準およびしきい値セットと比較します。検証結果はHarness内で表示し、他の監視システムや通知システムと統合できます。いずれかのメトリクスが指定したしきい値を超えた場合、Harnessはデプロイに失敗し、デプロイをロールバックできます。
これらの手順に従いHarness CDとPrometheusを統合し、Prometheusによって収集されたメトリクスに基づいてデプロイを検証できます。
Harness CDを使用してデプロイを検証するためのCV機能を実際に設定する方法を見てみましょう。
前提条件
- CD無料プランのHarnessアカウント
- サンプルアプリケーションをデプロイするためのKubernetesクラスターへのアクセス
- Prometheusエンドポイント(チュートリアルで入手方法を説明します)
Prometheusにアクセスできない場合は、KubernetesクラスターにPrometheusをインストールできます。
Helmを使用してPrometheusをインストールします。
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm upgrade --install prometheus prometheus-community/prometheus \
--namespace prometheus --create-namespace次のステップは、LoadBalancer経由でのPrometheusの公開です。
kubectl expose deployment -n prometheus prometheus-server --type=LoadBalancer --name=prometheus-serviceLoaddBalancerタイプでサービスを公開すると、Prometheusエンドポイントを簡単に取得でき、ダッシュボードでエンドポイントを確認できます。※GCPを使用してクラスターを作成しています。 チュートリアル
チュートリアル
このチュートリアルでは、検証ステップがローリングおよびカナリアデプロイ戦略でどのように機能するかを説明します。
Harness CDモジュールにサインアップして、パイプラインの作成を開始します。
 CVを行う前に、Kubernetesマニフェストをデプロイする方法を知っておく必要があります。このガイドに従って、簡単なCDパイプラインを作成してGrafanaインスタンスをデプロイします。
CVを行う前に、Kubernetesマニフェストをデプロイする方法を知っておく必要があります。このガイドに従って、簡単なCDパイプラインを作成してGrafanaインスタンスをデプロイします。
チュートリアルの説明に従って、プロジェクトとCDパイプラインを作成します。
最後に、CDパイプラインを構成した後、パイプラインを保存して実行し、デプロイが成功したことを確認できます。
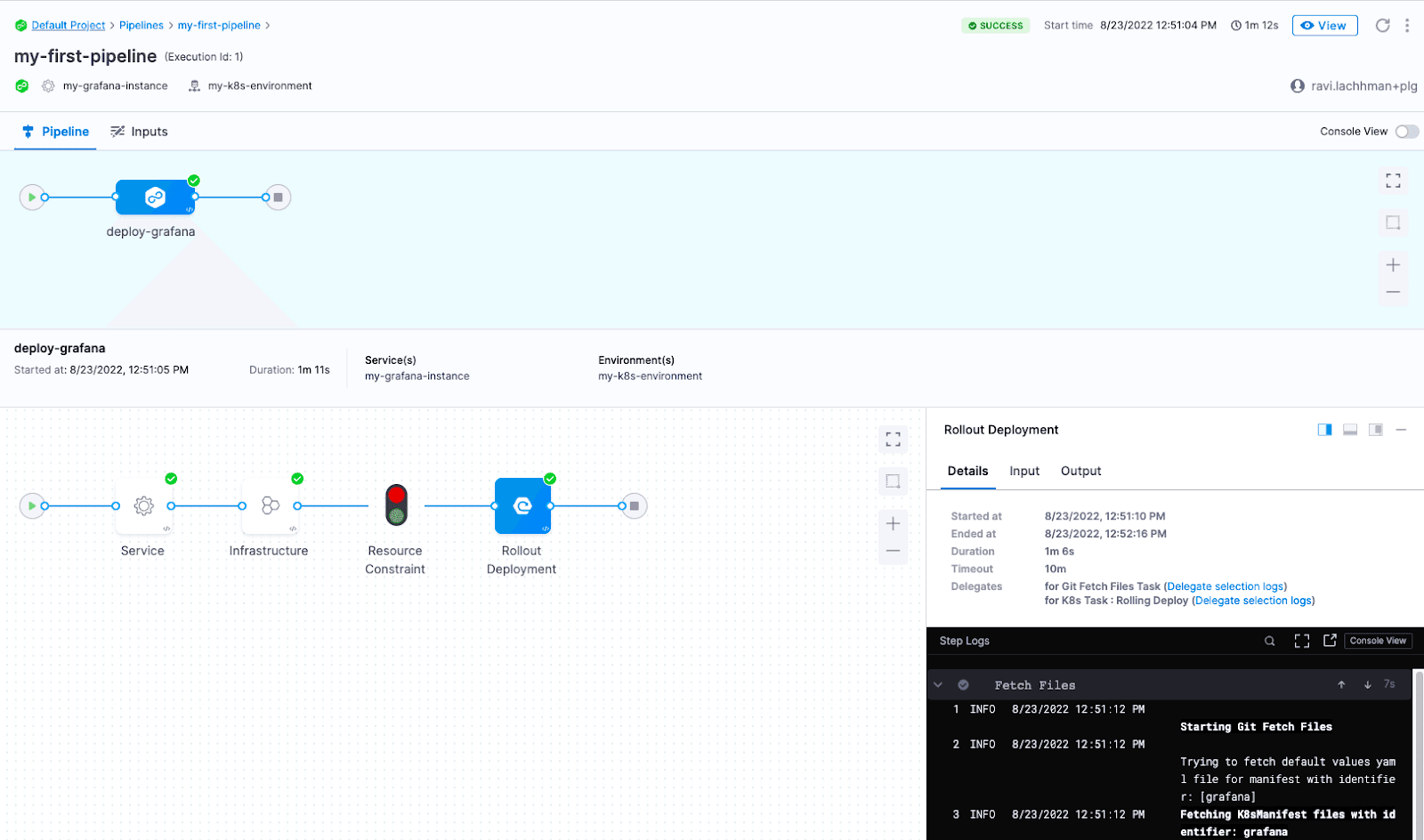 サービスをデプロイできました。デプロイの検証ステップを追加しましょう。
サービスをデプロイできました。デプロイの検証ステップを追加しましょう。
Continuous Verificationステップの追加
デプロイが成功したら、パイプラインを編集し、ステップライブラリーからCVステップを追加します。
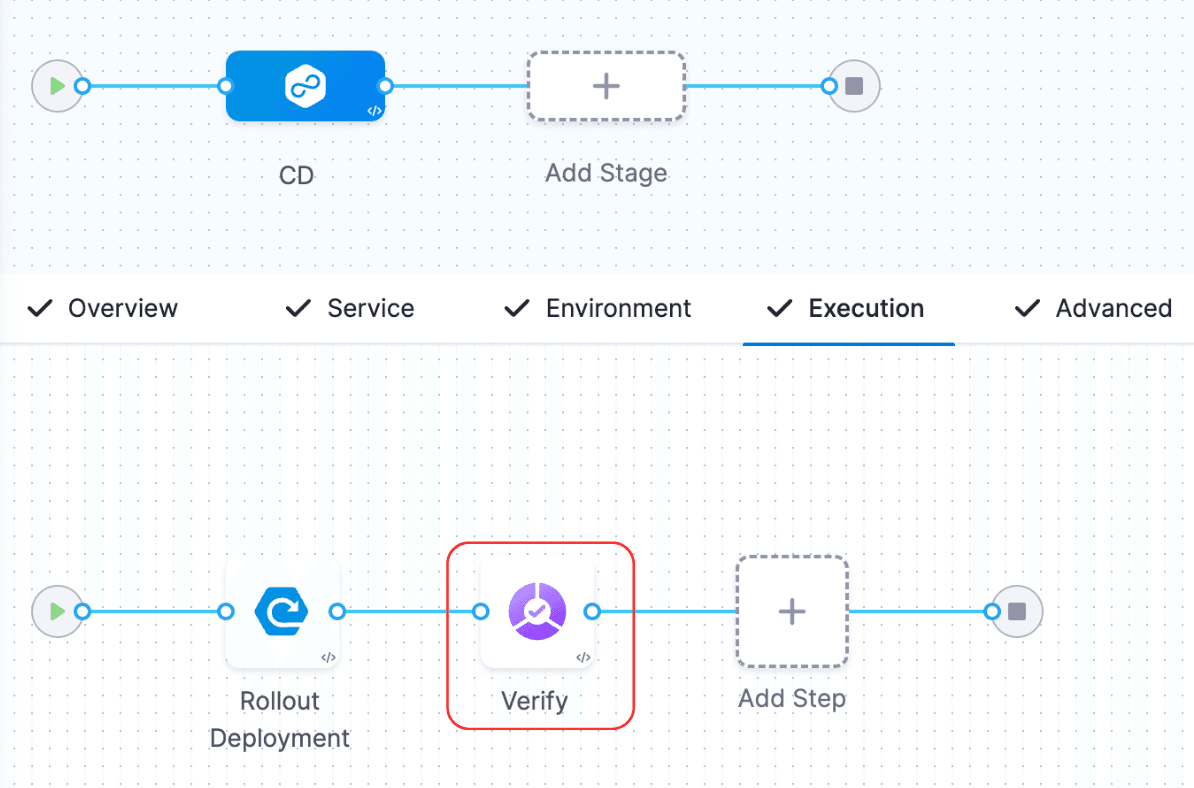 デプロイをローリングからカナリアに変更しましょう。新しい機能やソフトウェアをリリースする際には、その方がより効果的であると考えられています。
デプロイをローリングからカナリアに変更しましょう。新しい機能やソフトウェアをリリースする際には、その方がより効果的であると考えられています。
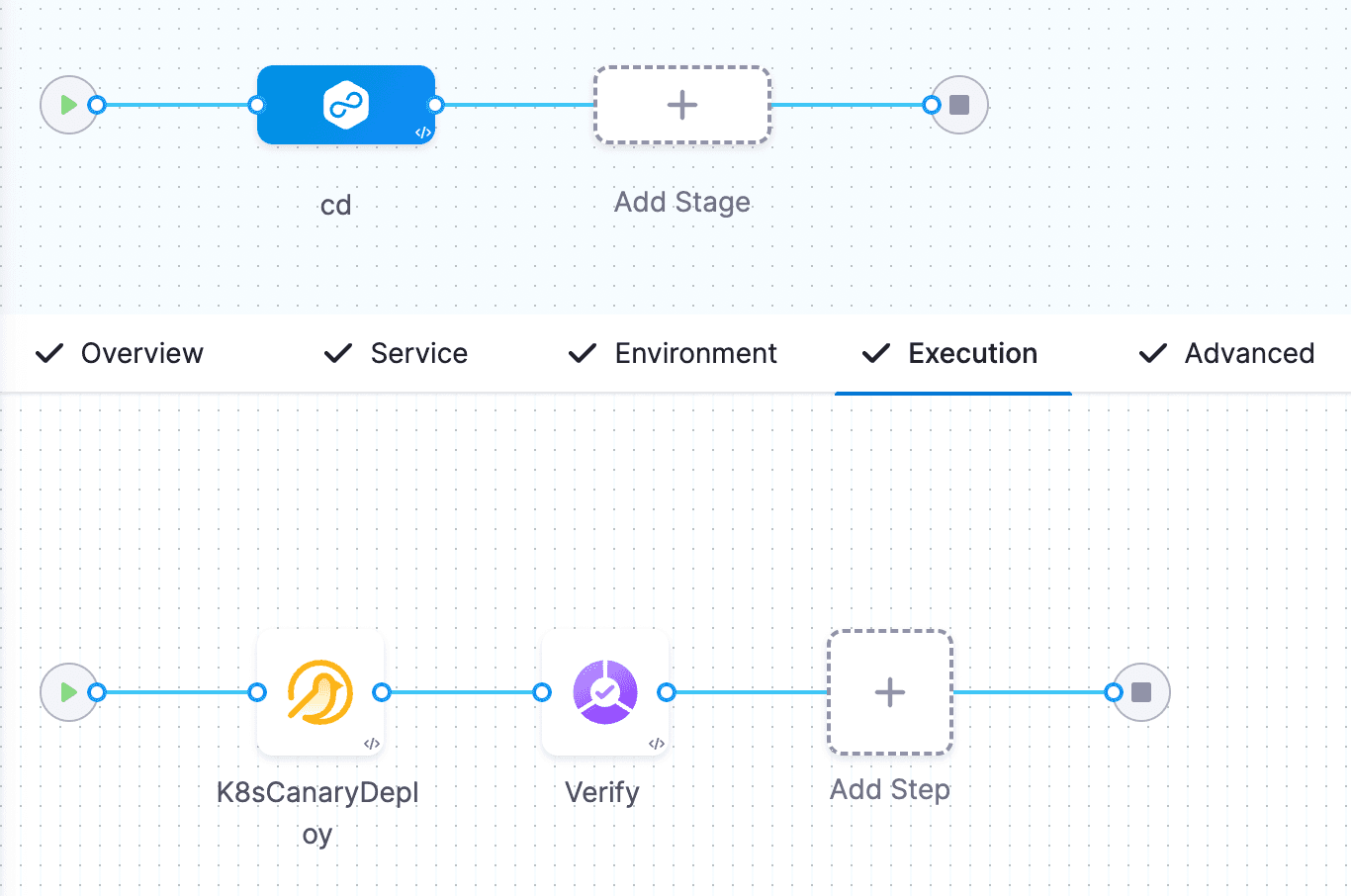 カナリアデプロイを行う理由
カナリアデプロイを行う理由
カナリアデプロイは、リスクを軽減し、新しいリリースの安定性を確保するためにCDで使用されるデプロイ戦略です。トラフィックの大部分を安定した既存のバージョンにルーティングしながら、アプリケーションの新しいバージョンをユーザーまたはサーバーのサブセットに段階的にロールアウトすることが含まれます。
Harness CDでは、分析と検証の結果に基づいて、段階的なロールアウトを続行してカナリアデプロイの範囲を拡大するか、問題が検出された場合にデプロイを完全にロールバックするかを決定できます。Prometheusメトリクスは、この意思決定プロセスにおいて重要な役割を果たします。
Harness CDでPrometheusモニタリングを備えたカナリアデプロイを使用すると、次の利点が得られます。
- リスクの軽減:カナリアデプロイを使用すると、制御された方法で新しいバージョンを段階的にテストでき、ユーザーベース全体に対�する問題やバグの影響を軽減できます。
- パフォーマンスの検証:Prometheusメトリクスを使用すると、安定バージョンと比較して新しいバージョンのパフォーマンスを評価し、必要な基準を満たしていることを確認できます。
- 意思決定の自動化:PrometheusをHarness CDと統合すると、分析と検証のプロセスを自動化し、事前定義されたルールとしきい値に基づいて導入の意思決定を行うことができます。
検証ステップでも、CVタイプをカナリアに変更しましょう。
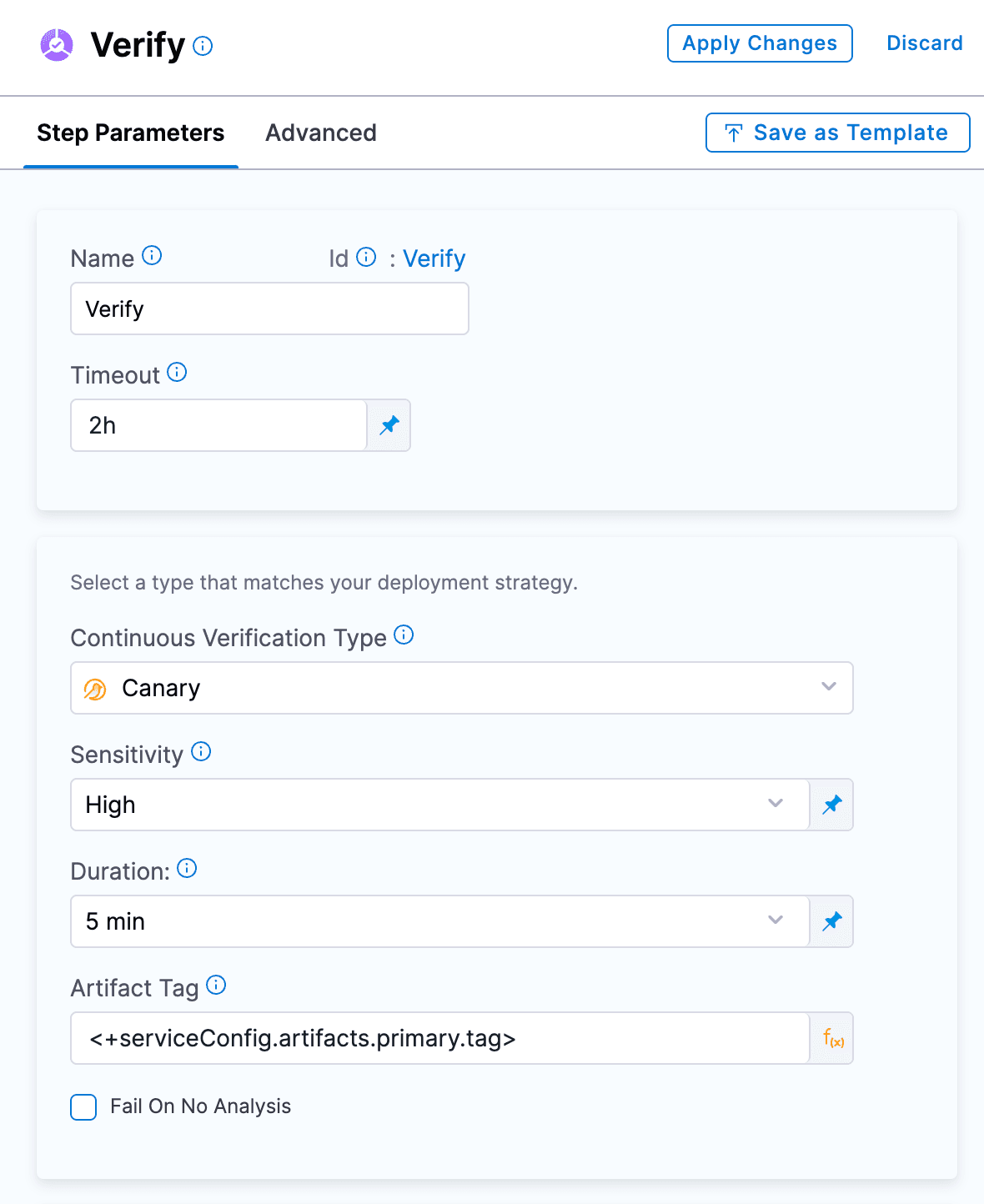 検証ステップに次の詳細を追加できます。
検証ステップに次の詳細を追加できます。
CVタイプ:カナリア
感度:高
期間:5分
アーティファクトタグ:
<+serviceConfig.artifacts.primary.tag>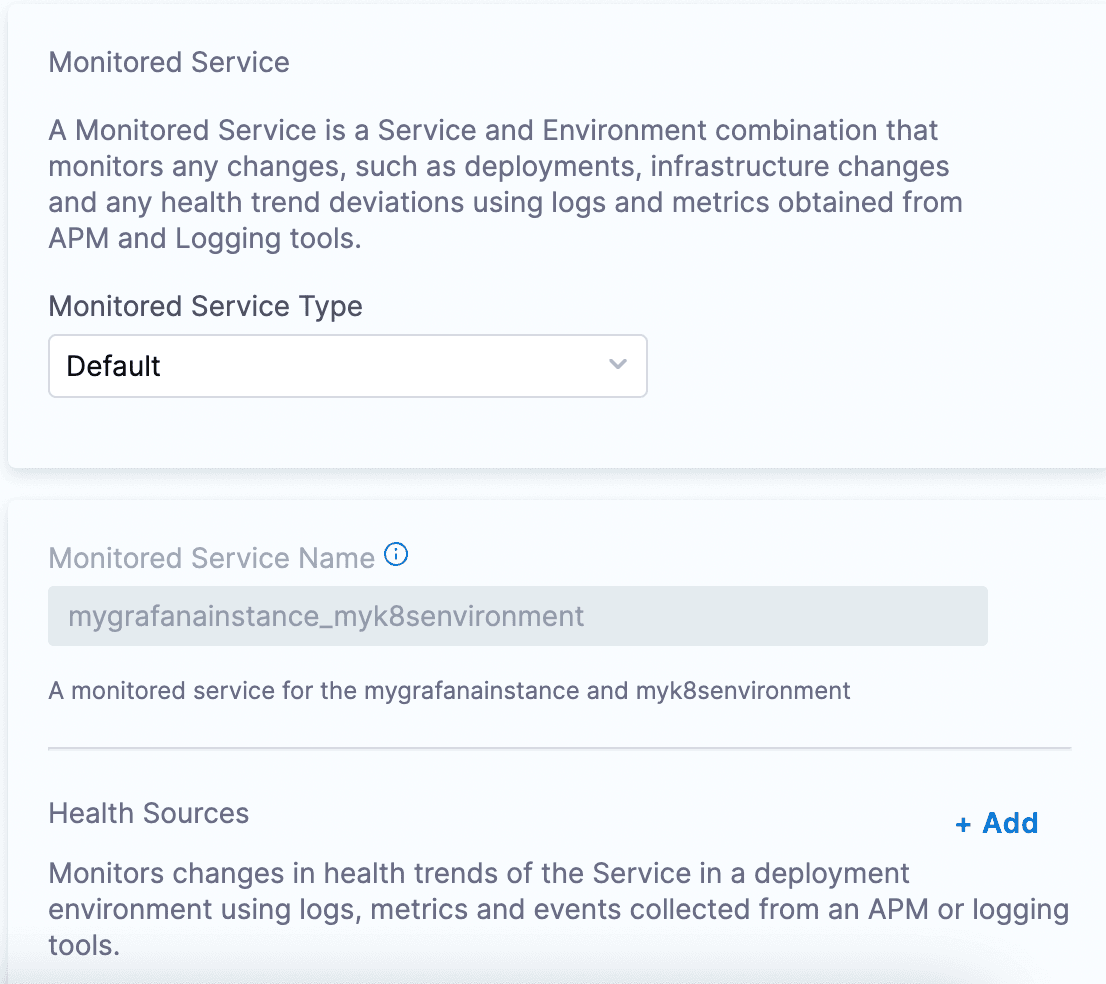 「+ Add」をクリックしてヘルスソースを追加できます。接続できるさまざまなヘルスおよびモニタリングツールが表示されます。自分にとって実現可能なものを選択してください。このチュートリアルでは、リストからPrometheusを選択します。
「+ Add」をクリックしてヘルスソースを追加できます。接続できるさまざまなヘルスおよびモニタリングツールが表示されます。自分にとって実現可能なものを選択してください。このチュートリアルでは、リストからPrometheusを選択します。
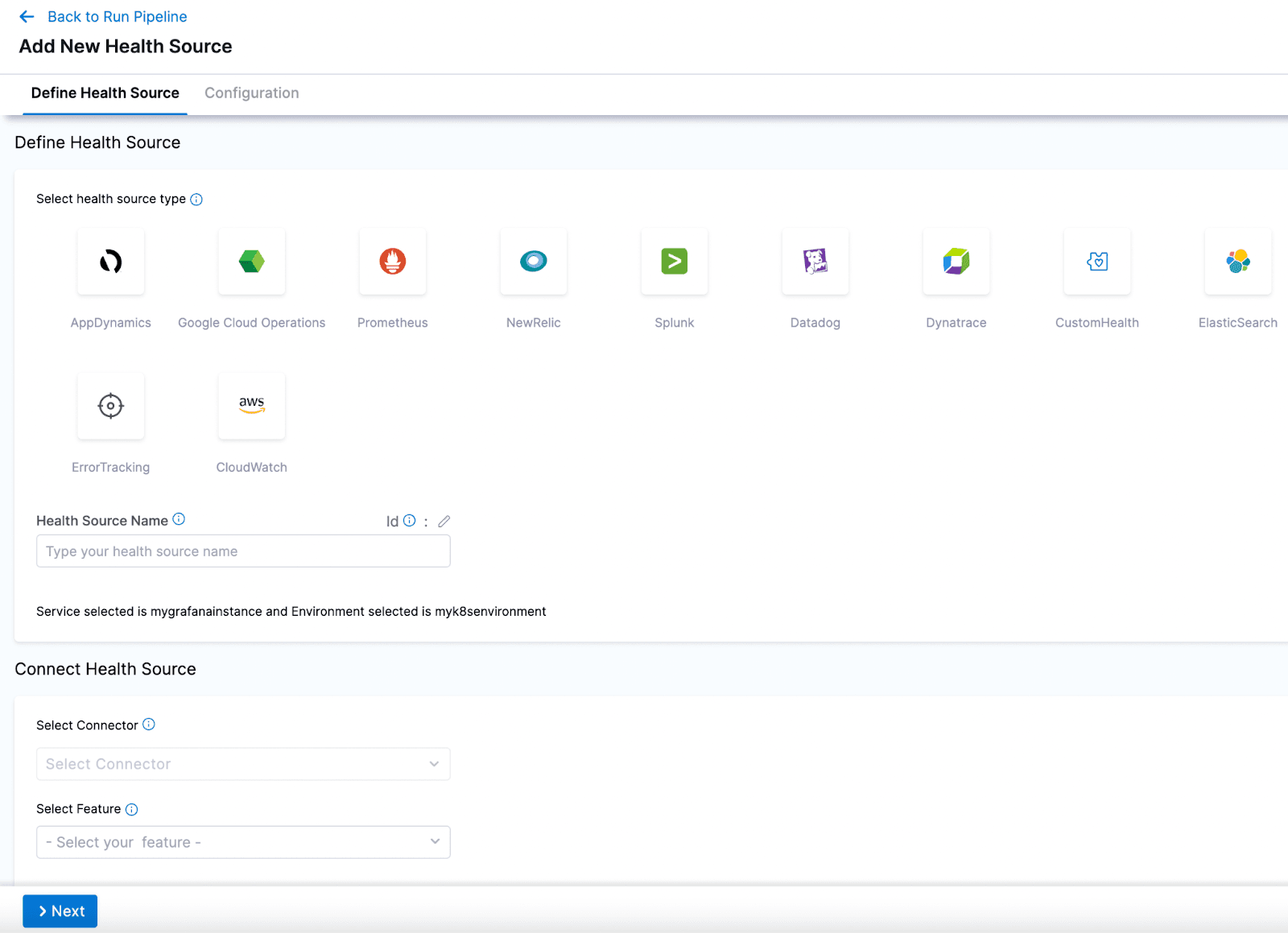 Prometheusを選択し、新しいPrometheusコネクターを作成します。Harnessはコネクターを使用して認証を行い、サードパ��ーティーツールで操作を実行します。Harnessはデリゲートを使用して、ネットワーク接続と認証を確立してコネクターをテストします。
Prometheusを選択し、新しいPrometheusコネクターを作成します。Harnessはコネクターを使用して認証を行い、サードパ��ーティーツールで操作を実行します。Harnessはデリゲートを使用して、ネットワーク接続と認証を確立してコネクターをテストします。
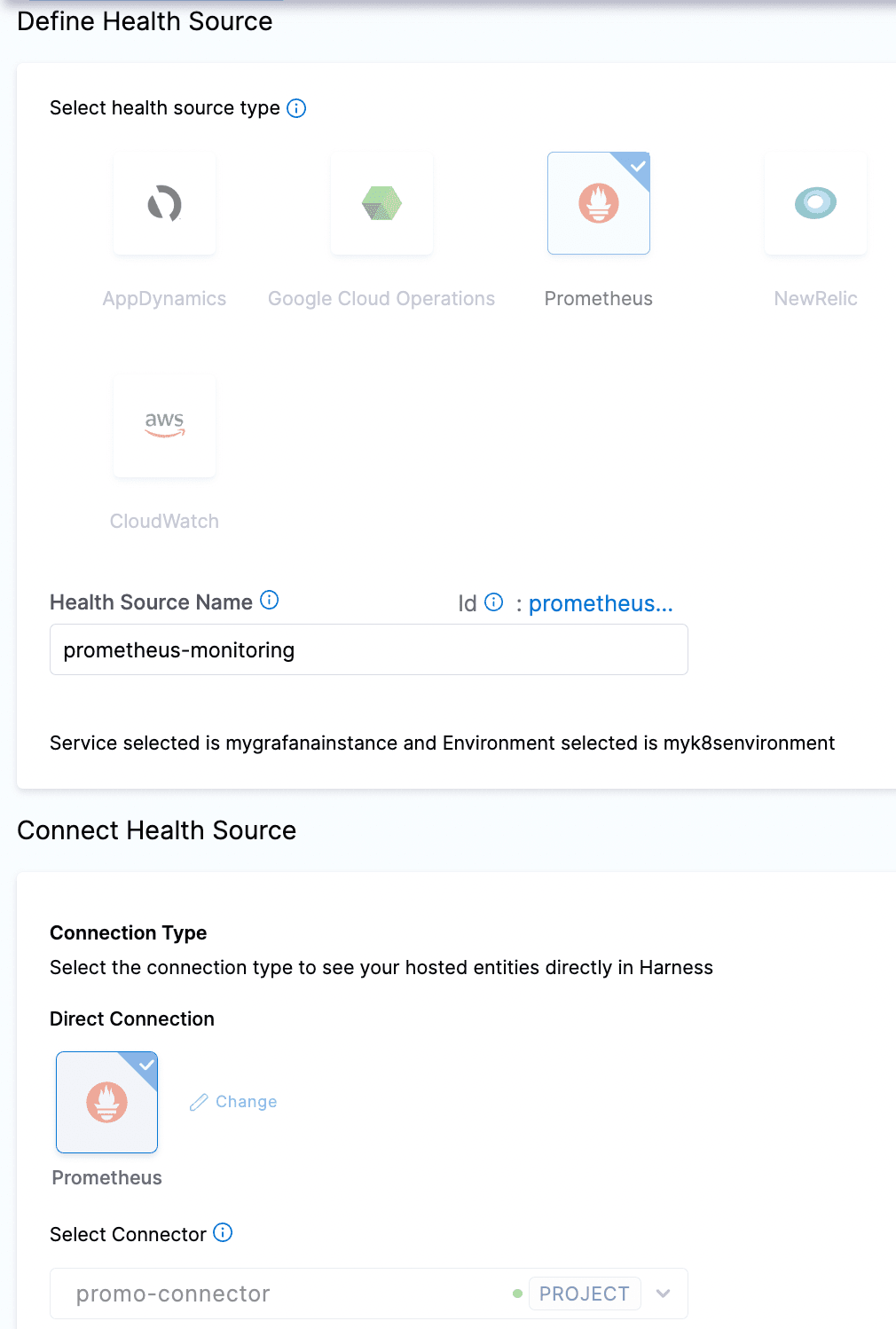 「promo-connector」はPrometheusコネクター名です。任意の名前を付けられます。このコネクターを作成してHarness Delegateに接続する方法を見てみましょう。
「promo-connector」はPrometheusコネクター名です。任意の名前を付けられます。このコネクターを作成してHarness Delegateに接続する方法を見てみましょう。
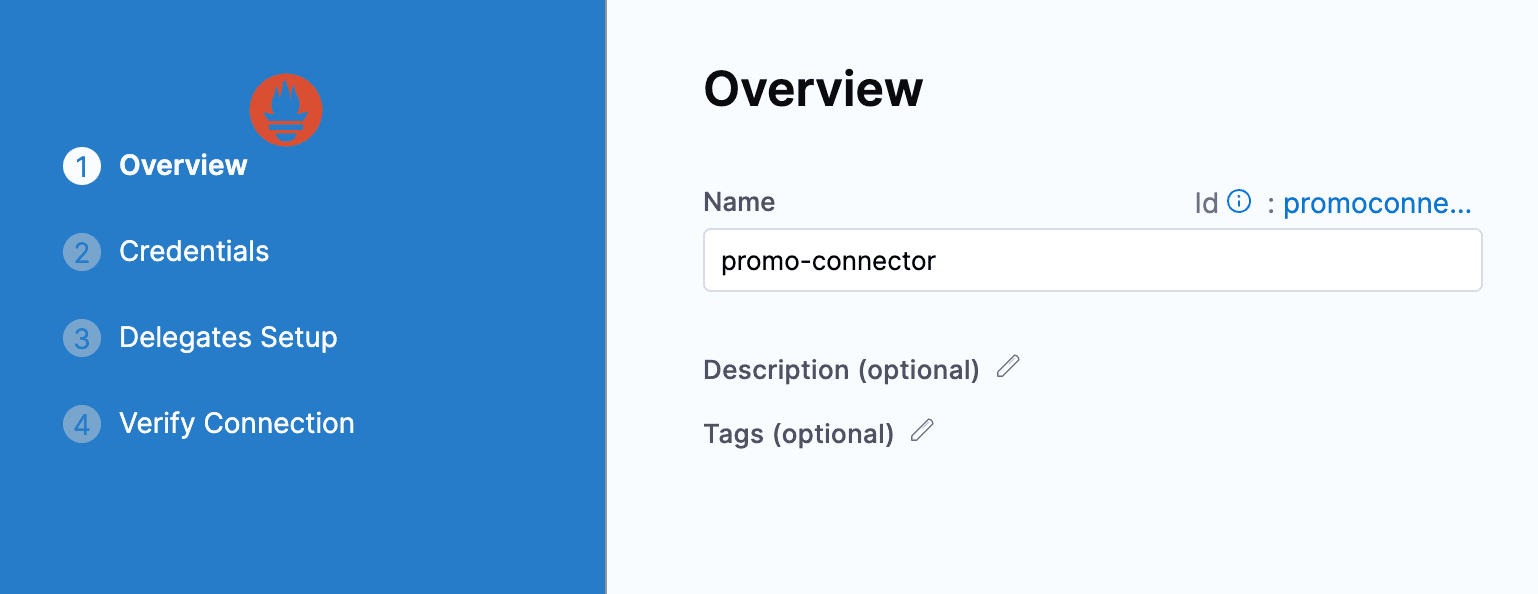 PrometheusエンドポイントURLを共有します。
PrometheusエンドポイントURLを共有します。
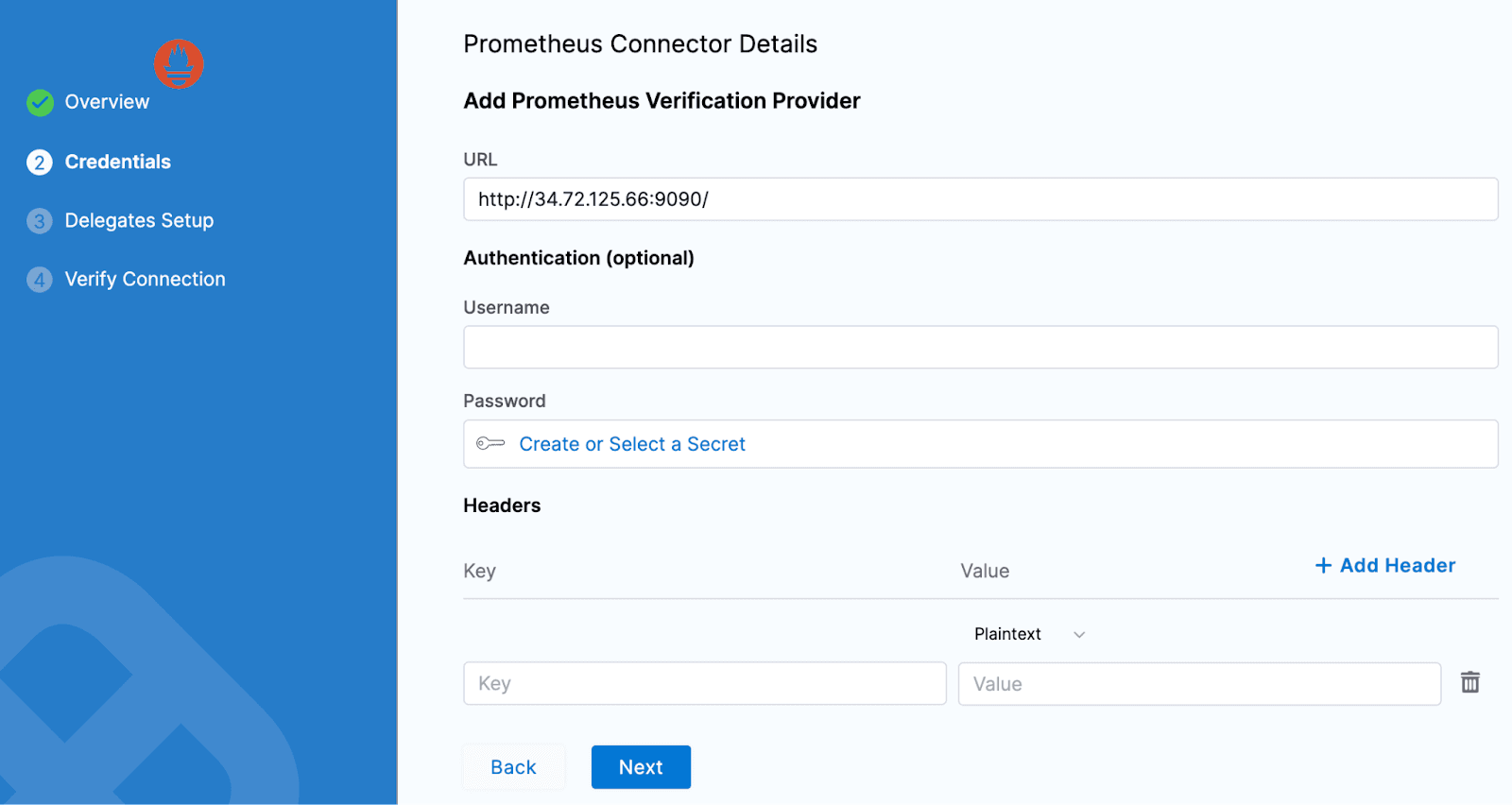 利用可能なデリゲートに接続します。
利用可能なデリゲートに接続します。
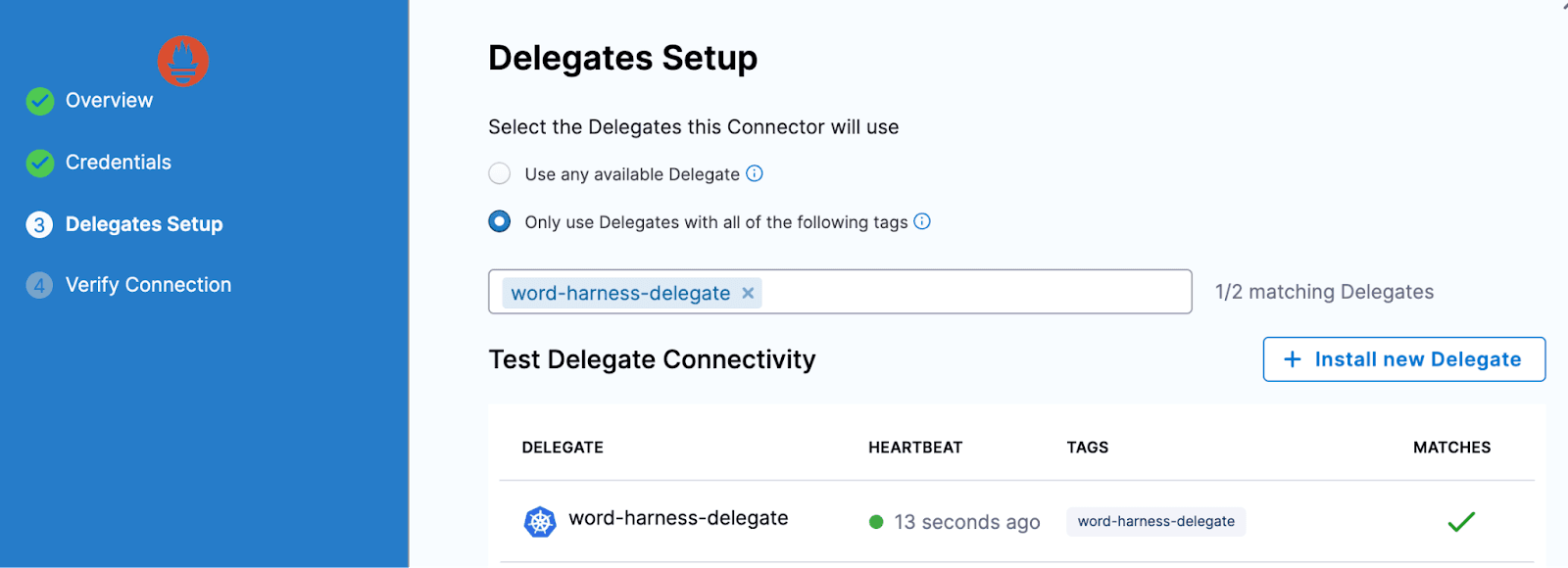 デリゲートへの接続が成功したことを確認してください。
デリゲートへの接続が成功したことを確認してください。
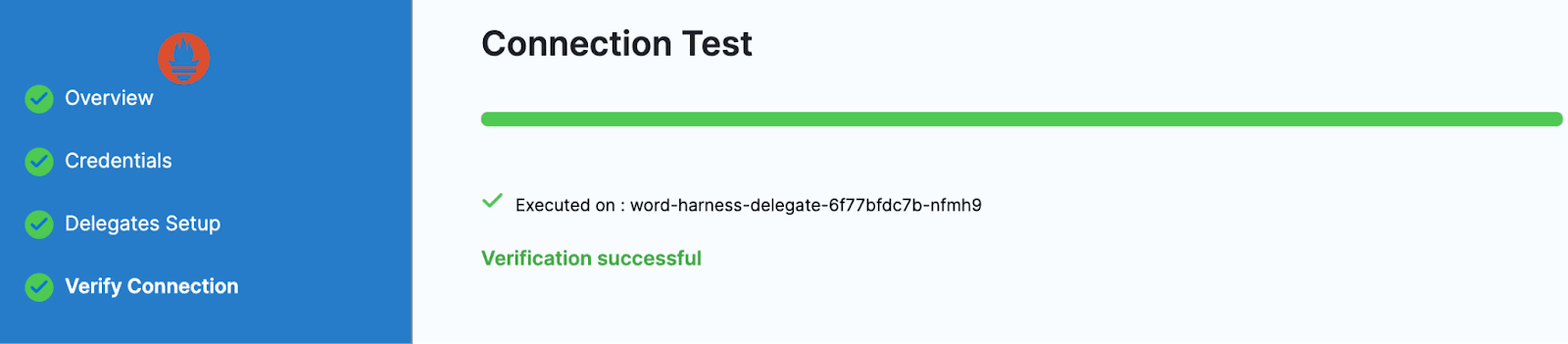 Prometheusコネクターが正常に追加されました。
Prometheusコネクターが正常に追加されました。
次の画面に進��むと、クエリー構成ページが表示されます。
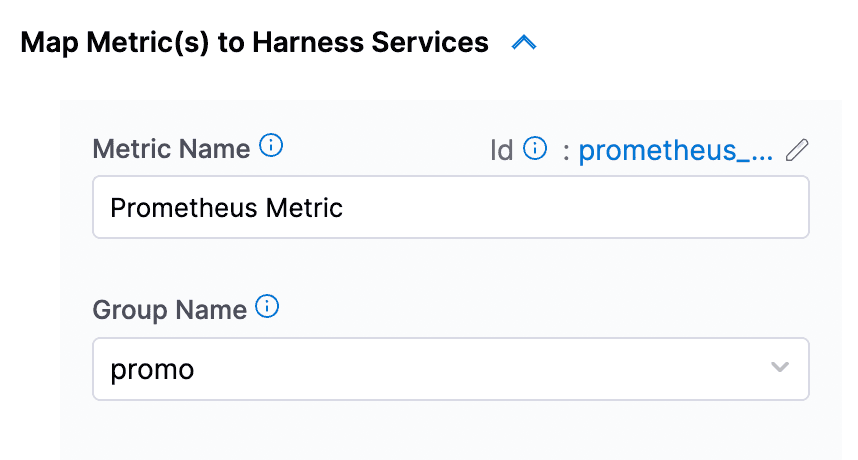
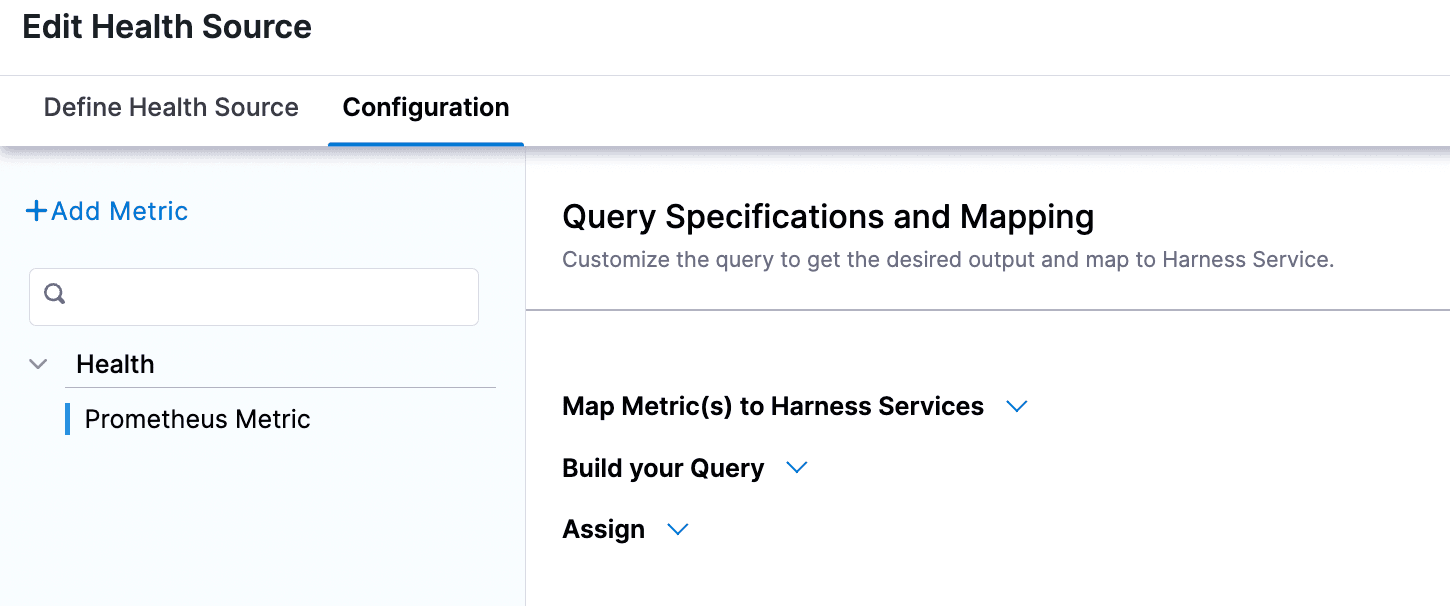 必要な詳細を全て追加し、クエリーを作成します。グループ名を作成する必要があります。クエリータブを編集して、以下のクエリー文字列を追加できます。
必要な詳細を全て追加し、クエリーを作成します。グループ名を作成する必要があります。クエリータブを編集して、以下のクエリー文字列を追加できます。
max(
CV_Counter_Example_total {
app="harness-cv-prom-example"
})
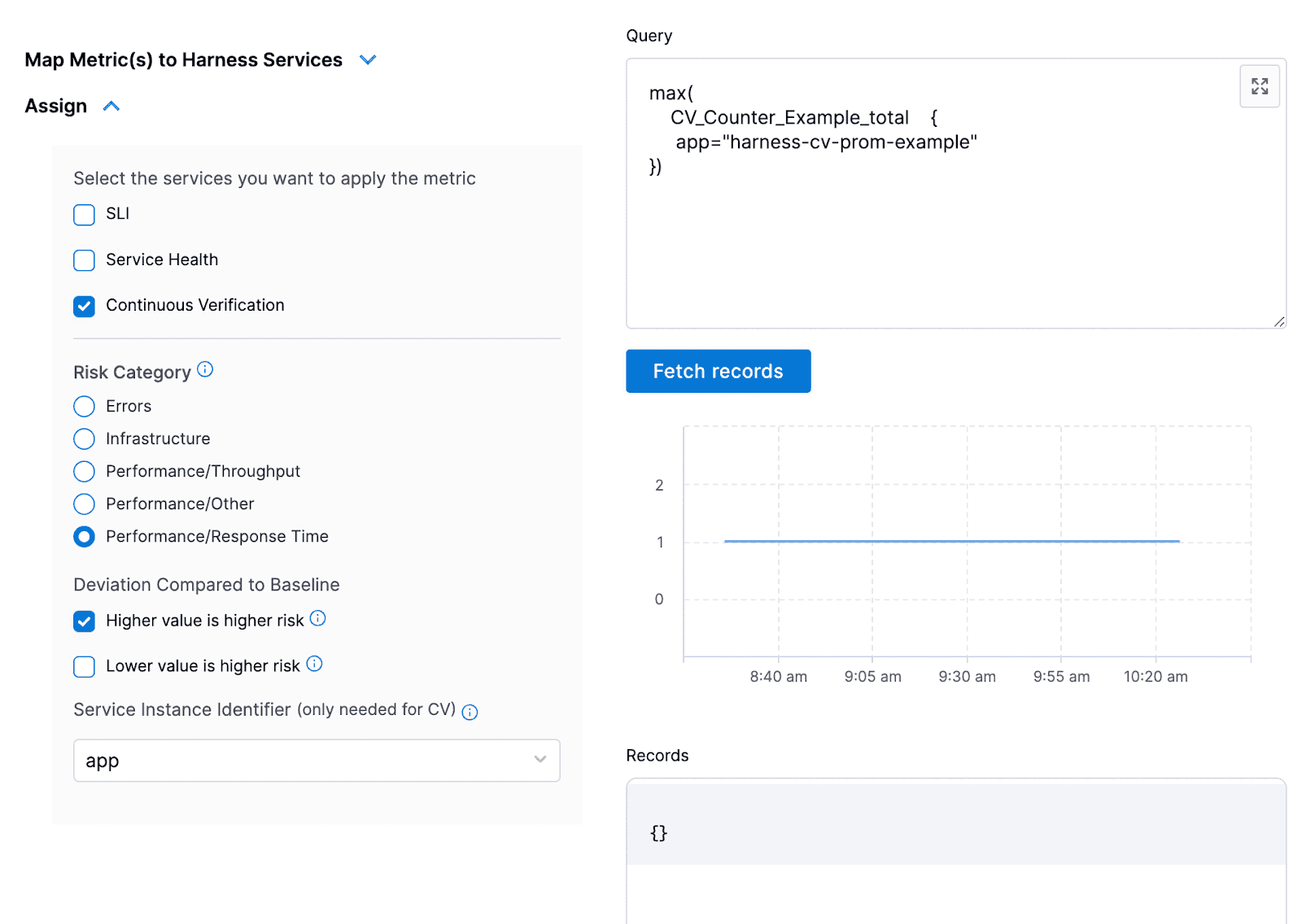 パイプラインを送信して保存し、パイプラインを実行します。
パイプラインを送信して保存し、パイプラインを実行します。
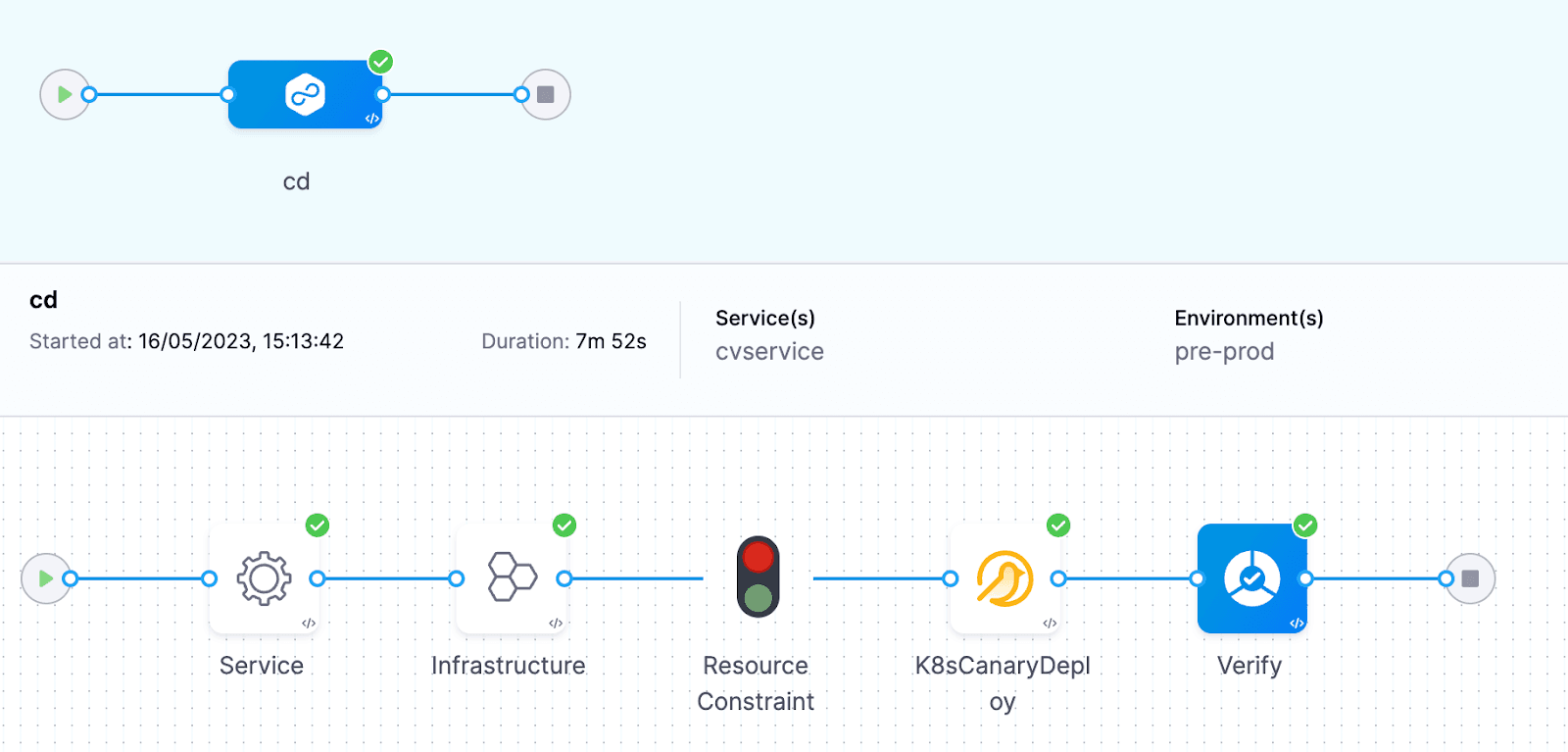 異常が検出された場合は、このコンソールビューで見つけることができます。
異常が検出された場合は、このコンソールビューで見つけることができます。
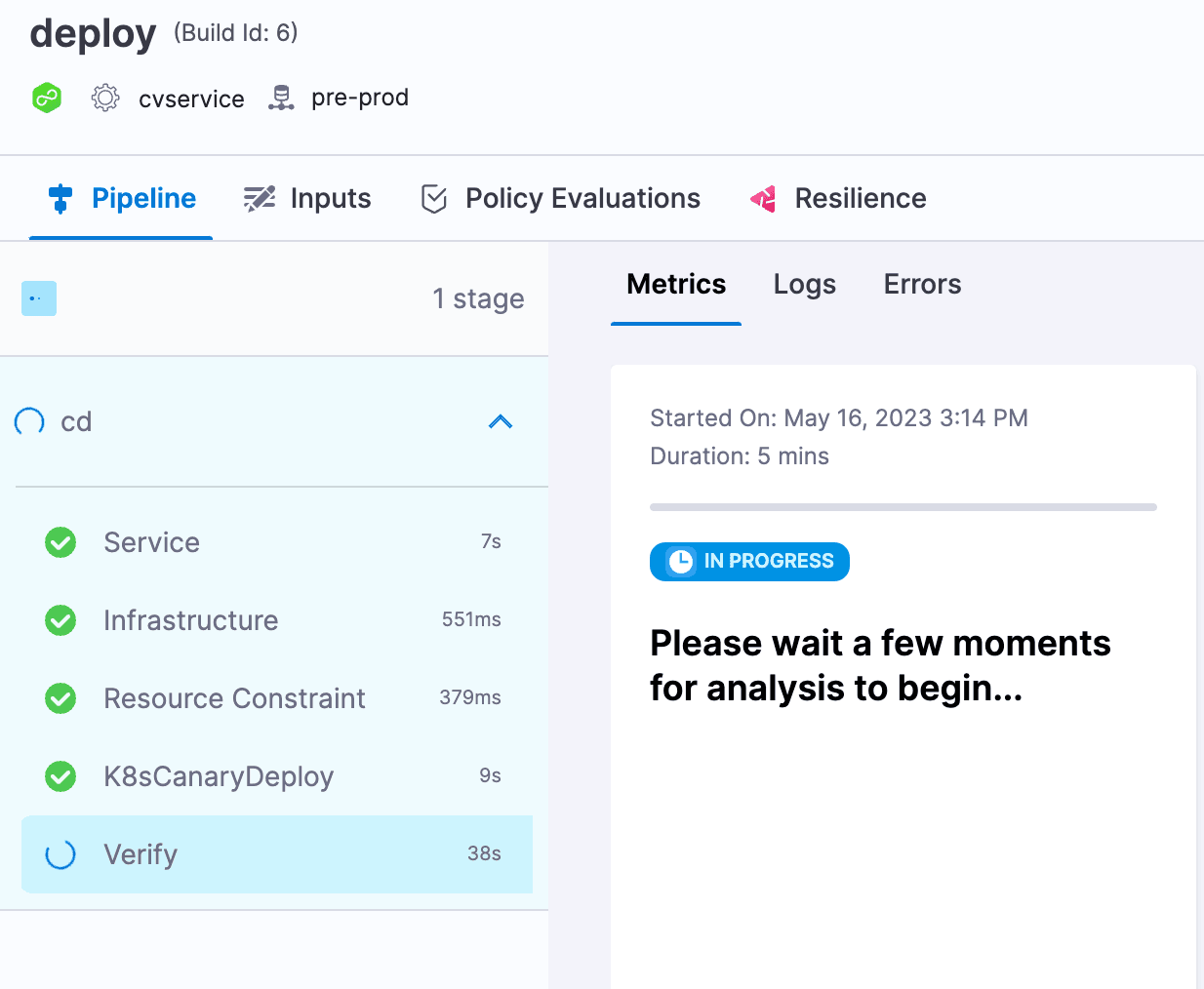 ログの検証には時間がかかりますが、最終的にはCVステップで成功したパイプラインを確認できます。
ログの検証には時間がかかりますが、最終的にはCVステップで成功したパイプラインを確認できます。
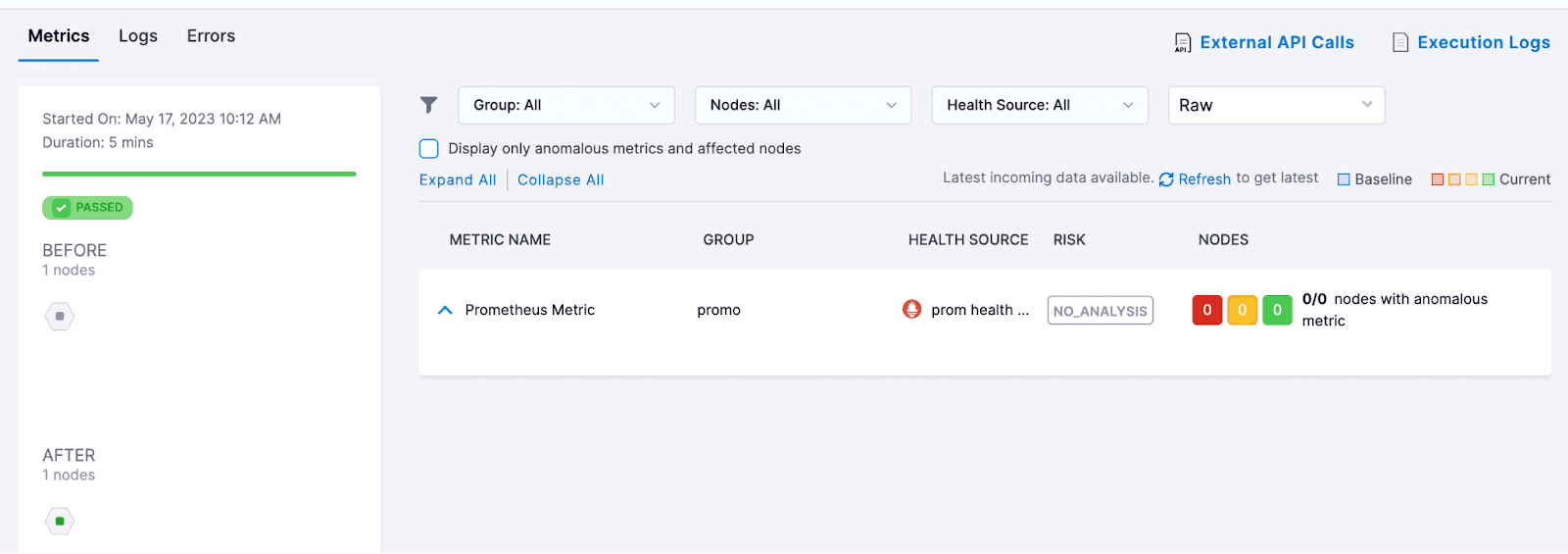 メトリクスをデプロイして詳細を表示します。
メトリクスをデプロイして詳細を表示します。
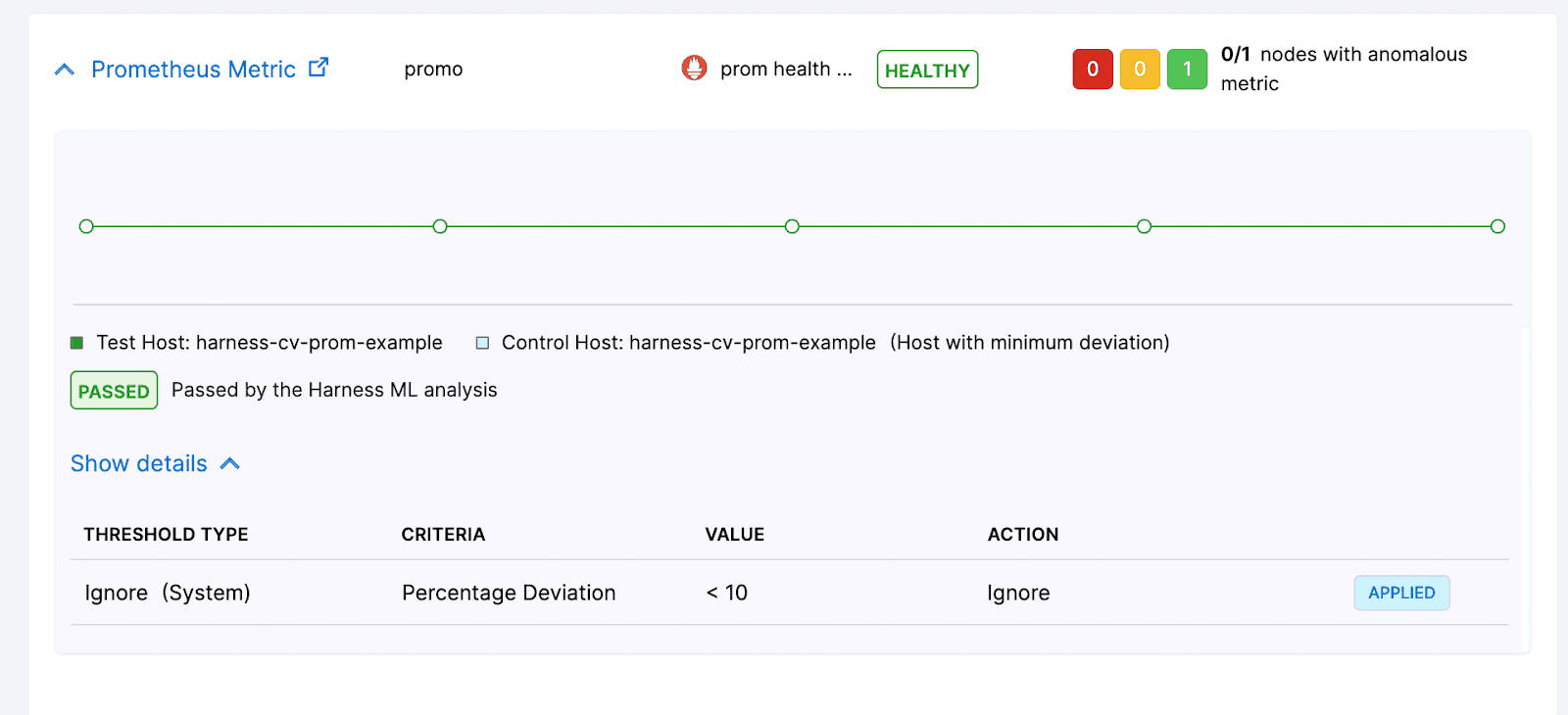 また、外部API呼び出しや実行ログを簡単にチェックして、リアルタイムイベントを確認することもできます。
また、外部API呼び出しや実行ログを簡単にチェックして、リアルタイムイベントを確認することもできます。
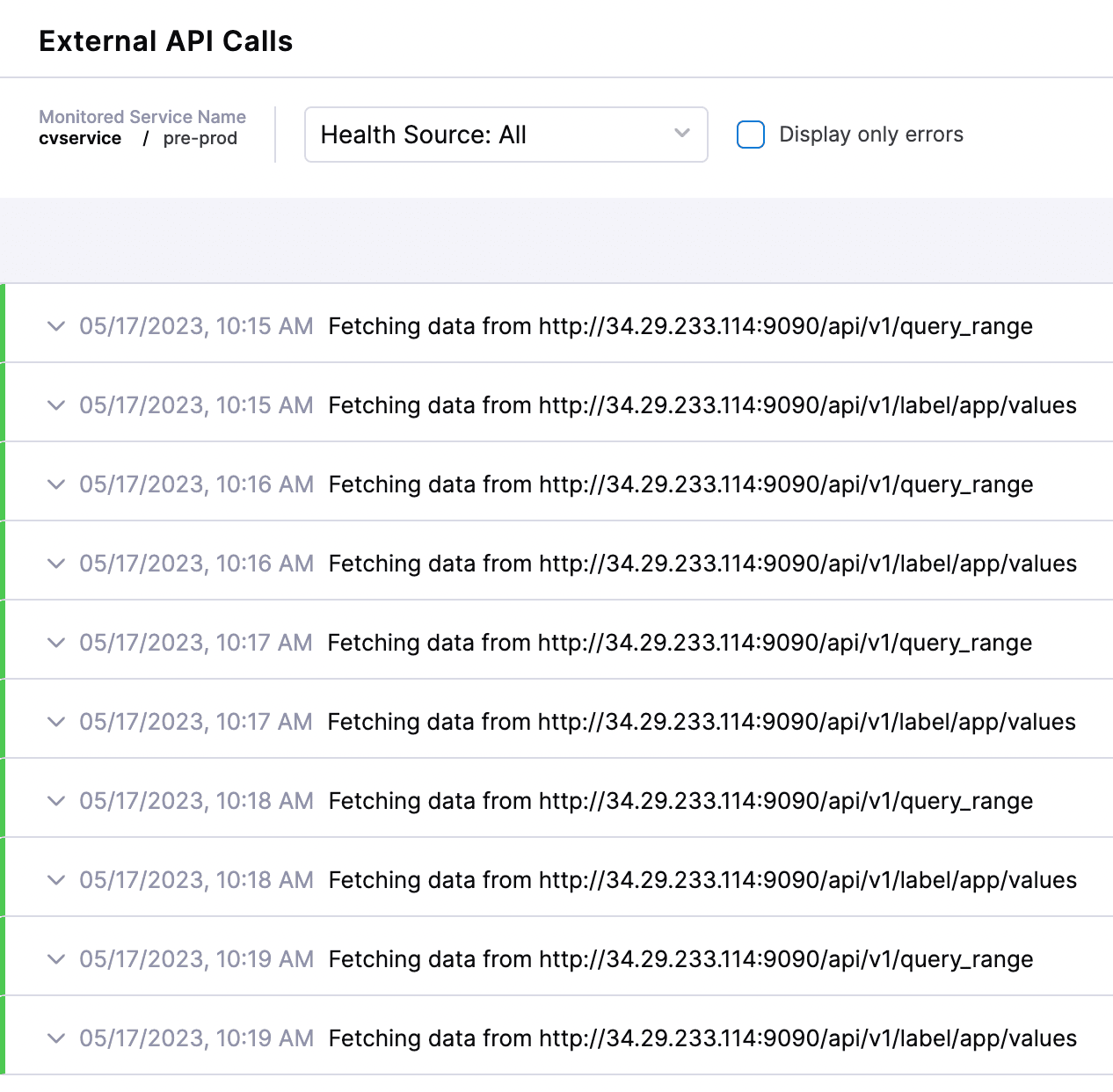
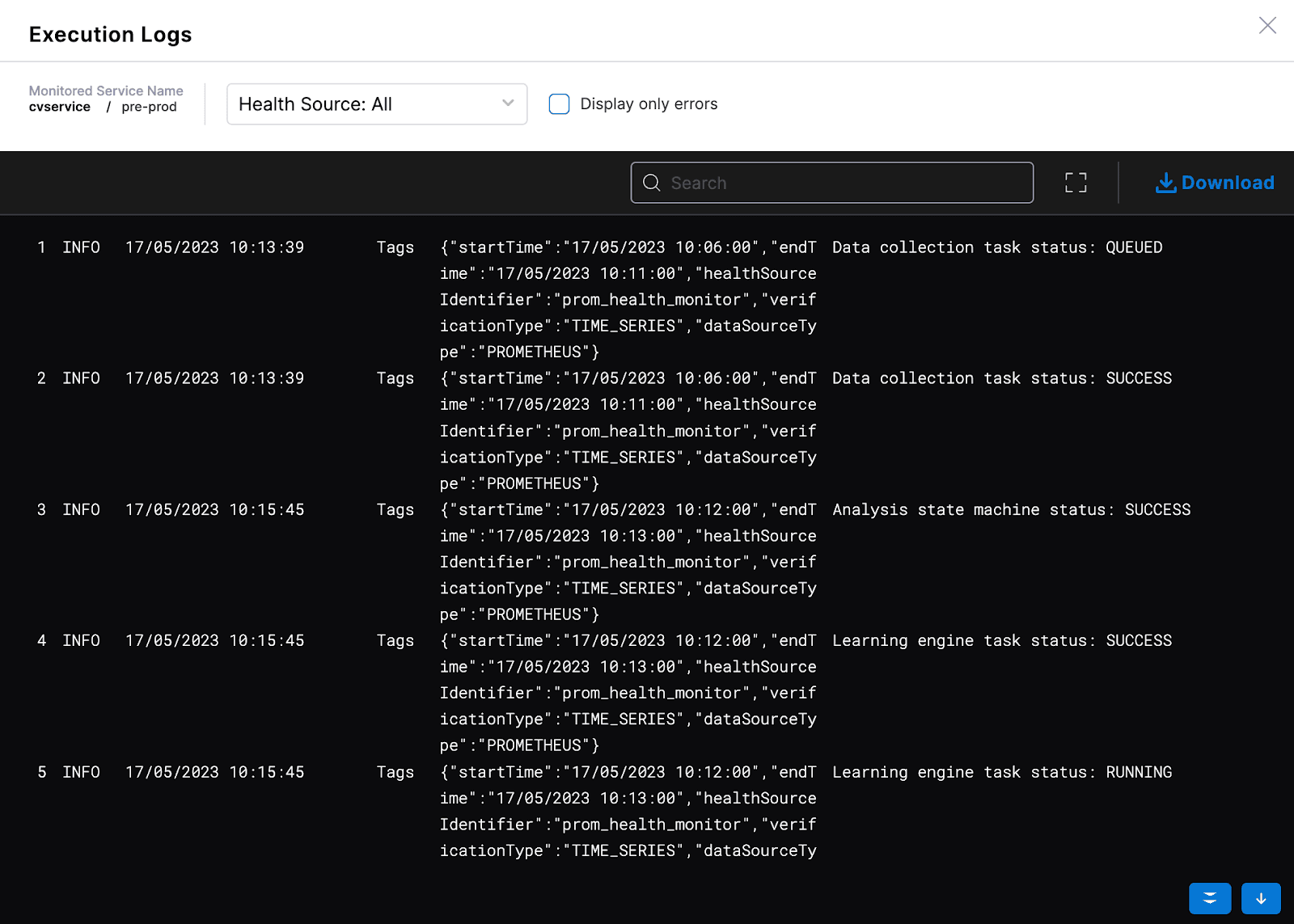 同様に、Splunk、NewRelic、Datadog、AppDymanicsなどの他の監視ツールを追加できます。
同様に、Splunk、NewRelic、Datadog、AppDymanicsなどの他の監視ツールを追加できます。
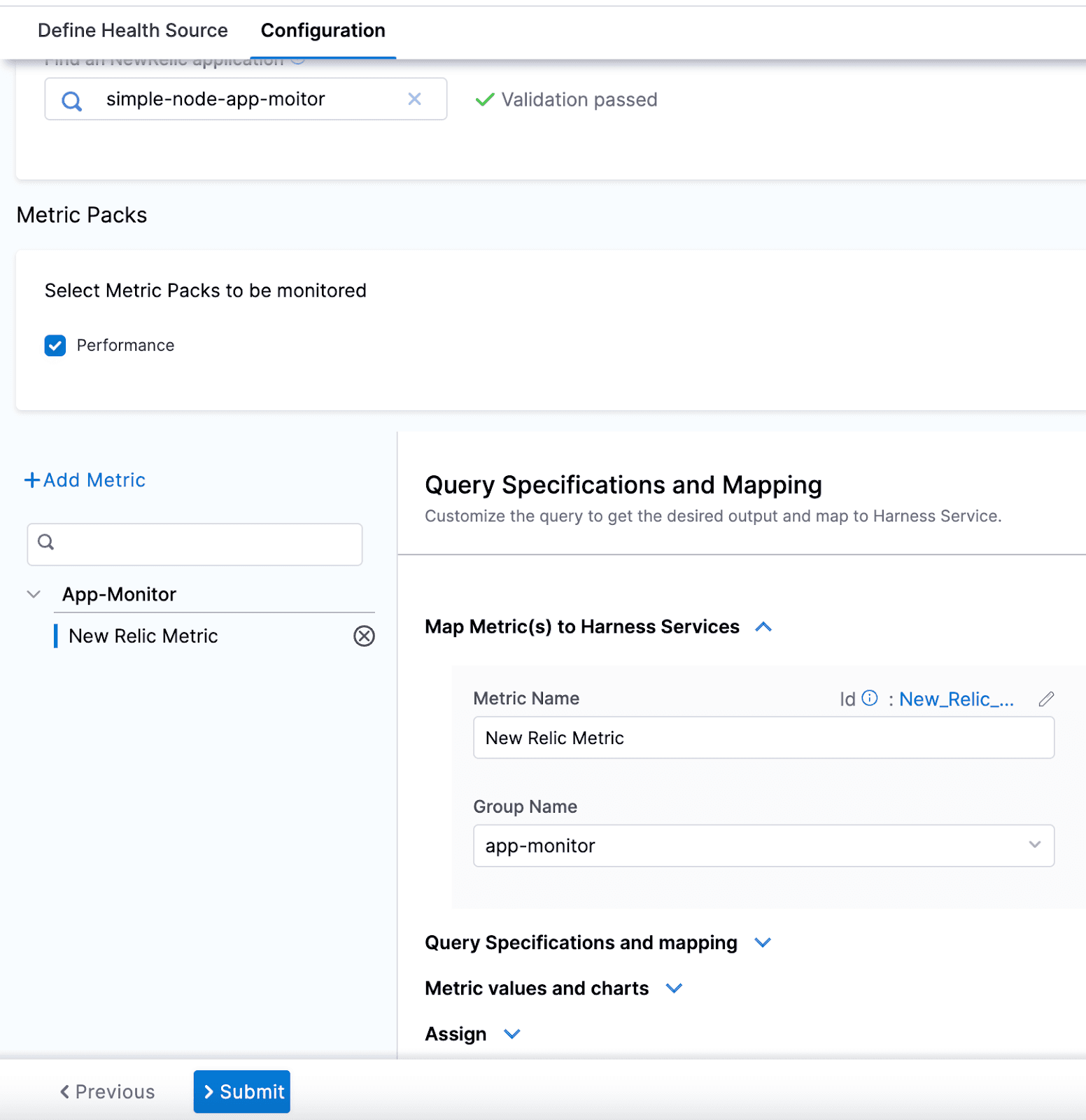
NewRelicモニタリング:検証ステップの失敗シナリオ
サンプル Node.js アプリケーションを使用してNewRelicモニタリングソースをセットアップする例も取り上げました。
前のチュートリアルで行ったように、全てを通常通りに実行し、検証ステップでヘルスソースとしてNewRelicを追加しました。アプリケーションはカナリアデプロイ戦略に従ってデプロイされています。検証ステップが失敗した場合に何が起こるかを説明しましょう。
 これがパイプラインの様子です。
これがパイプラインの様子です。
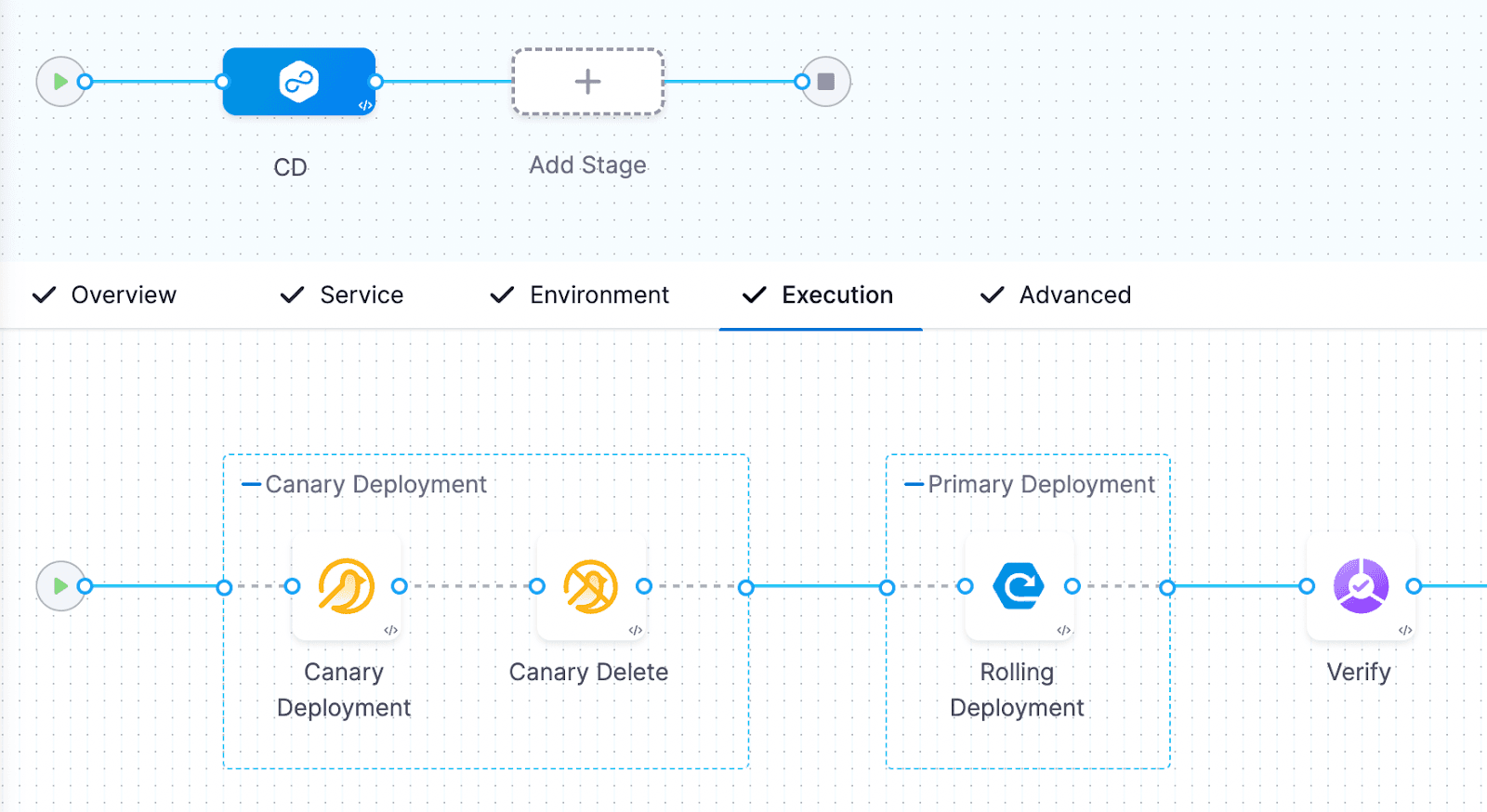 検証が失敗した場合にパイプラインがどのように動作するかを理解しやすくするために、ここでは意図的に検証ステップを失敗させています。
検証が失敗した場合にパイプラインがどのように動作するかを理解しやすくするために、ここでは意図的に検証ステップを失敗させています。
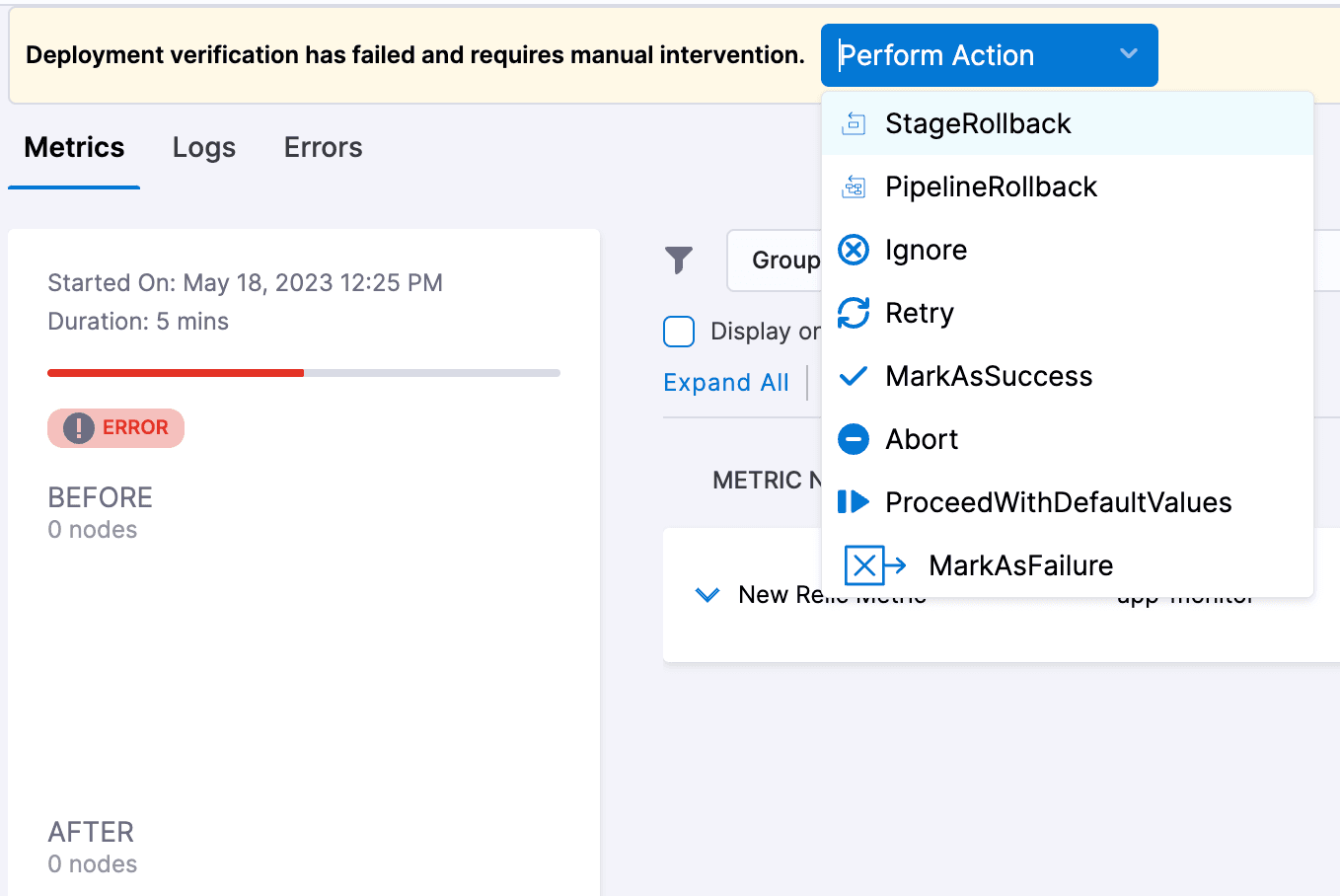
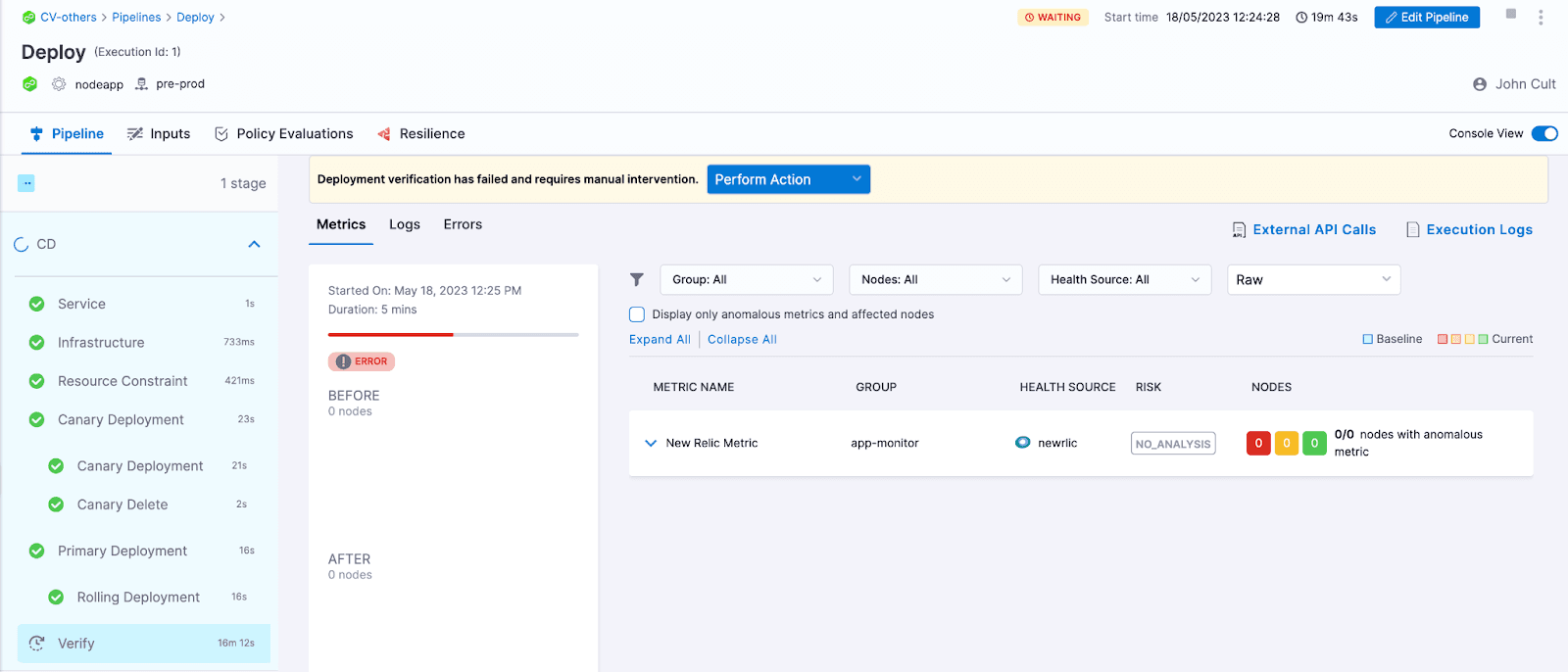 次に、表示された利用可能なアクションを実行する必要があります。ロールバック、無視、再試行、成功としてマークする、中止する、デフォルト値で続行する、または失敗としてマークできます。
次に、表示された利用可能なアクションを実行する必要があります。ロールバック、無視、再試行、成功としてマークする、中止する、デフォルト値で続行する、または失敗としてマークできます。
検証が失敗した場合にここでどのようなアクションを実行するかは、チームによって異なります。
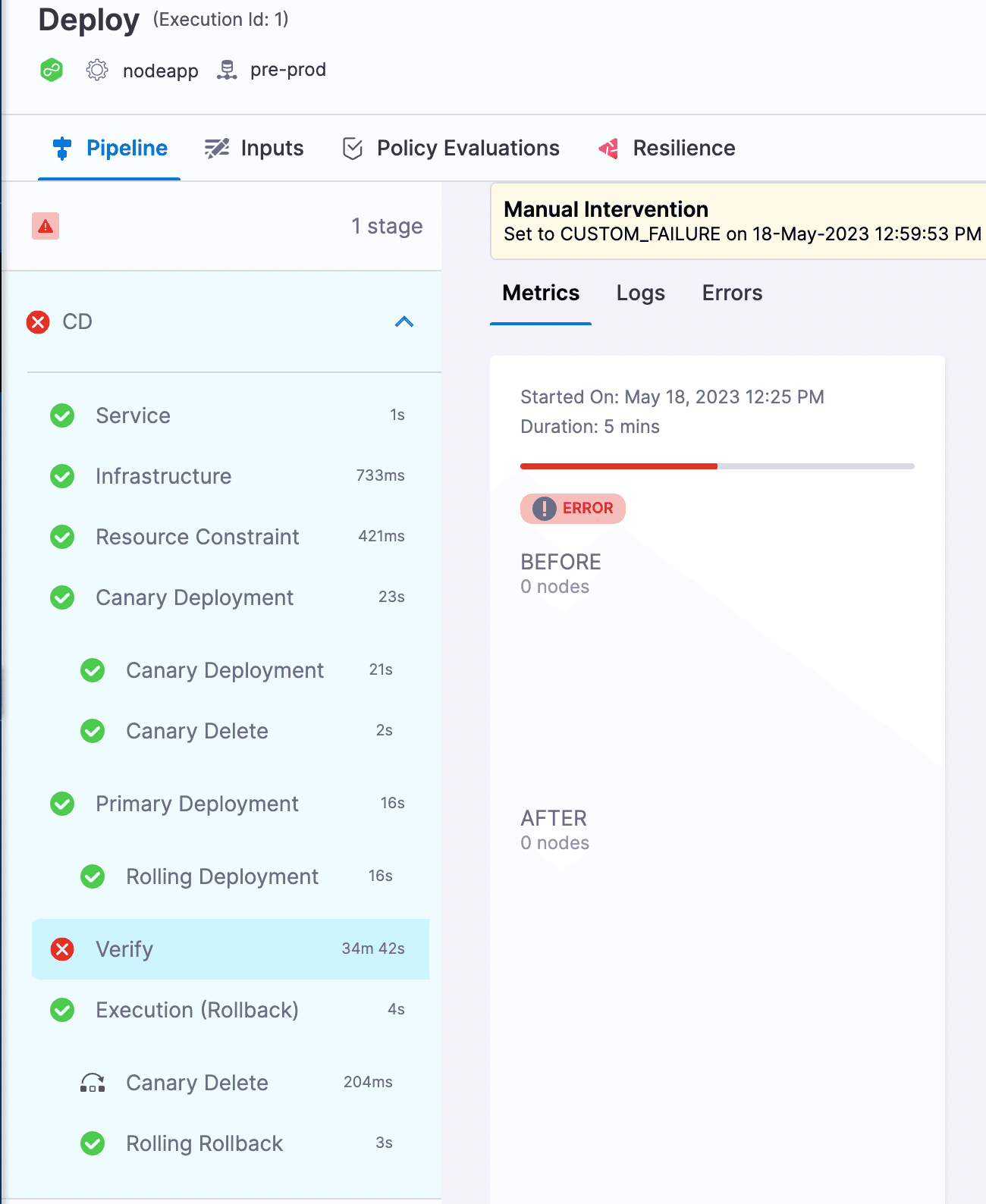
 この場合、上で述べたように、手動で介入して適切なアクションを選択できます。ここでは「StageRollback」を選択しました。以下にパイプラインの実行が表示されます。
この場合、上で述べたように、手動で介入して適切なアクションを選択できます。ここでは「StageRollback」を選択しました。以下にパイプラインの実行が表示されます。
 Harness CVは、マルチサービスデプロイなどの複雑なデプロイがある場合に非常にうまく機能します。Harness CVでは、さまざまなロギングツールや監視ツールを接続してデプロイを検証することができます。多くの組織はデプロイ後の監視を真剣に考えていませんが、これによりアプリケーションやサービスを自信を持ってデプロイでき、他の組織よりも優位に立つことができます。
Harness CVは、マルチサービスデプロイなどの複雑なデプロイがある場合に非常にうまく機能します。Harness CVでは、さまざまなロギングツールや監視ツールを接続してデプロイを検証することができます。多くの組織はデプロイ後の監視を真剣に考えていませんが、これによりアプリケーションやサービスを自信を持ってデプロイでき、他の組織よりも優位に立つことができます。
この記事はHarness社のウェブサイトで公開されているものをDigital Stacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。