

2022年1月28日
Feature Flags
Feature Flagsのベストプラクティス(機能トグル)
実運用でのテスト、トランクベースの開発、デフォルトでのフィーチャーフラグの使用 - これらは全て、フィーチャーフラグのベストプラクティスです。今すぐ詳細を学び、あなたのフィーチャーフラグ体験を可能な限り有益なものにしましょう!
これまでにも、「意外と知らないフィーチャーフラグの5つの活用例」「フィーチャーフラグを使った本番環境でのテスト」「Progressive Delivery。 Canariesとフィーチャーフラグ 」など、フィーチャーフラグについて多くの記事を書いてきました。 しかし今日は、チームが成熟し、フィーチャーフラグを立てることが標準になってきたときに、よりよい結果を得られるよう、より高度なフィーチャーフラグのベストプラクティスを提供するために時間をとりたいと思います。
これらのヒントは、ソフトウェアチームが、機能トグルの実装、機能テストの拡張、アクセス制御のためのシステム動作の制御、あるいは単に新しい機能をユーザー全体にロールアウトしようとしているか��どうかにかかわらず、フィーチャーフラグを使ってより良く制御できるようになることを目的としています。
フィーチャーフラグに関してちょっと再確認
まずは、フィーチャーフラグのベストプラクティスを紹介する前に、フィーチャーフラグについて同じ考えを持っていることを確認しましょう。
フィーチャーフラグとは?
フィーチャーフラグは、開発者がコード(またはコードパス)の特定の部分を条件付きでオンまたはオフにできる手段です。フィーチャーフラグは、継続的デリバリーの延長線上にあると考えられます。つまり、変更をフラグの後ろに置いて、後で制御された方法でオンにする(あるいは同じ方法で隠したり削除したりする)方法です。これらは、フィーチャーフラグ管理の基礎的な考えを成しています。
フィーチャーフラグを使っているのか、フィーチャーフラギングを行っているのか、よくわからない?他の一般的な用語としては、フィーチャートグル、リリーストグル、実験トグルなどがあります。状況によっては、ops toggleやexperiment toggleもあります。また、(ビルドか購入かに関わらず)本式のフィーチャーフラグソリューションを使っていない人は、フィーチャーフラグが設定ファイルの変数として表現されているのを見るかもしれません。
あなたが使っているフィーチャーフラグや機能トグルのバージョンが何であれ、最終的にはフィーチャーフラグのアプローチを使うメリットを引き出したいと思っているはずです。
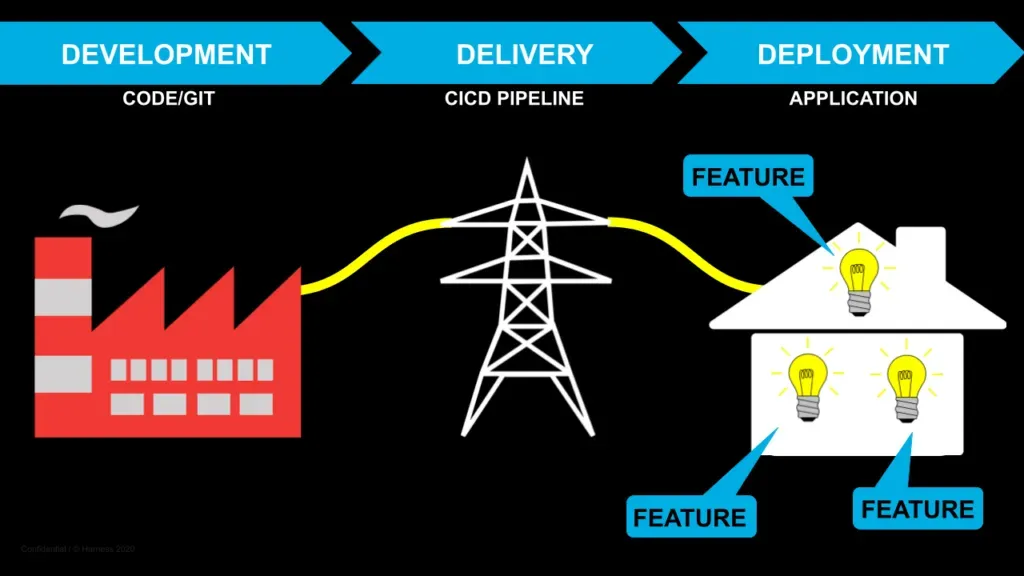
ソフトウェアのデリバリーライフサイクル - ちょうど家庭に電気を供給するようなものです。
本番でのメリット
一般的に、チームがフィーチャーフラグを採用する理由は、デリバリーの速さを上げ、さらにそのリスクを低減させたいからです。フラグの後ろにさまざまな機能を配置することで、チームはコードをより小さな単位で、より頻繁にデプロイできるようになり、複数の「セーブポイント」を作り、さまざまな機能をまだ準備ができていない場合にも本番環境に移行できるようになります。フィーチャーフラグは、変更が本番環境に導入された時点で、チームにとってのコントロールポイントとなります。
フィーチャーフラグを使うと、エンジニアリング側でいくつかのことがすぐに分かります。
- 速度が上がります。機能ブランチのマージが早くなり、不完全な機能の隔離を心配することなく、より頻繁にデプロイできるようになるからです。
- カスタムスクリプトや他の秘密の管理者コマンドの代わりにフィーチャーフラグを使うことで、環境間で変更の状態を簡単に制御できるようになります。
- PMやマネージャーなどの関係者にフィーチャ�ーフラグを渡して、いつオンにするかを決めてもらえば、途中で止められることはありません。
そして、組織の他の部分にも、同様に効果が現れるでしょう。
- 実験的な機能やベータ版の機能に対して誰でもフィーチャーフラグを使えるようにすることで、エンジニアの待機や応答を待つことなく、より迅速に顧客にサービスを提供できるようになります。
- PMやマーケティングチームは、エンジニアリング部門との費用と時間のかかる立ち上げの調整を必要とせず、リリースを完全に自分のものにできるため、リリース調整が大幅に簡素化されます。
- 重要な新機能の設定に共通のUIを提供するフィーチャーフラグにより、誰もが、何がどこで利用可能かをより明確に把握できるようになります。
フィーチャーフラグは、小さいけれど大きな力を持っています。フィーチャーフラグとは何か、どのように、いつ使うか、制作現場でフィーチャーフラグを使うメリットと課題については、Feature Flags 101 eBookで詳しく説明しています。
フィーチャーフラグのベストプラクティス
新機能のネーミング
フィーチャーフラグには多くの利点がありますが、多くの場合、チームはそれを管理しようと思いません。開発が進んで古いフラグが多くなり、もはやトグルされない安定したコードの上に残されているという状態になるまで考えもしないのです。これは、組織の規模が大きくなるにつれて、本番環境が非常に汚れたものになり、フィーチャーフラ�グシステムを使う価値が損なわれることにつながります。もし、フィーチャーフラグの理念が開発のスピードアップとリスクの低減にあるなら、システムを肥大化させることはそれに逆行するのではないでしょうか?
何を整理したいのかが分かっている場合でも、特定のフィーチャーフラグが何をするものなのかが分からないことがよくあります。これは、フィーチャーフラグの名前がエンジニアリングに特化したもの(「NEXT_OLD_GEO3」のようなもの)であることが多いためです。フィーチャーフラグの管理を容易にするために、フィーチャーフラグに人が読みやすい名前を付けることをお勧めします。これだけでは肥大化という潜在的な問題は解決できませんが、フィーチャーフラグの場所が簡単に分かることは、タイムリーなクリーンアップやライフサイクル管理を可能にする一歩になります。
一例として、ユーザー向けの新機能にフラグを立てる場合、社内で技術に弱いユーザーがその機能を識別できるような名前をフラグに付けます。フィーチャーフラグを扱うのは、常にエンジニアとは限らないことを忘れないでください。上記の例では、NEXT_OLD_GEO3 がフィーチャーフラグ上の地域を限定したターゲットグループを指していて、フラグを反転させるとヨーロッパのユーザー向けのフィーチャーフラグのセットをオンにするとします。チームは、プライバシーまたはGDPRに準拠した新しい機能セットの提供しようとしており、ヨーロッパのユーザーベースの実際の本番データでそれらをテストしたいと考えています。しかし、時間が経つにつれ、その機能が本番環境に定着するにつれて、このフラグは��段階的に廃止していくことになるでしょう。この1つのフラグだけで、他の50のフラグを全てひっくり返してしまうかもしれないのです。このフラグを見つけて機能を反転させて、それを掃除するのがいかに大変か、想像がつくでしょう。ここで、このフラグを"Privacy Features – Europe"と呼ぶ方が、より合理的かもしれません。
最終的には、個々のフィーチャーフラグを見つけやすくすることが重要で、特に非エンジニアリングユーザーがそれを利用する場合はそうです。
フィーチャーフラグ地獄を回避する
また、多くのチームが陥りがちなのが、「古いフラグ」を誰が削除するのか、明確な社内プロセスや合意を形成していないことです。また、そのプロセスをどの程度の頻度で行うかも定まっていません。このため、チームはフィーチャーフラグが多すぎると感じたり、フィーチャーフラグ地獄から抜け出せないと感じたりすることがよくあります。特に本番環境において、より多くのフィーチャーフラグを作り、恩恵を得たいのであれば、このような状態は望ましくありません。
フラグの利点の1つは、全社的なチームがフラグをさまざまなシナリオで使えることです。例えば、ユーザーの動作をテストするための実験トグル、運用トグル、システムの動作を変更するためのバックエンドフラグなどです。
しかし、多くの新機能が追加され、誰でもフィーチャーフラグを実装できるようになると、フィーチャーフラグがアプリケーションのコードのあちこちに散らばってしまうという欠点があります。フィーチャーフラグがコードベース全体に広がってしまうことに加え、それらの新しいフィーチャーフラグがコードに設置されるたびに、フィーチャーフラグ管理システムも大きくなっていきます。つまり、組織内でフィーチャーフラグの利用が拡大するにつれて、衛生を保つ必要がある場所が2つ出てくるのです。
フィーチャーフラグが多すぎるということはないと思いますが、新しい機能ごとに新しいフラグを立ち上げる際には、古くなったフィーチャーフラグや不要なフラグ、古くなったフィーチャーフラグを確実に削除するようにしたいものです。そうすれば、フィーチャーフラグシステムの肥大化に伴うデメリットを回避し、利益を享受し続けることができます。
こういったことを前もって話し合っておくべきです。
- 古くなったフラグをどれくらいの頻度で削除するのか?
- 誰が責任を持つのか?
- フラグの種類によって、所有者は異なるのか?
- 決して削除してはいけない永久フィーチャーフラグはどれか?
Facebook、Pinterest、Netflixなどの大企業は、データを収集し、ユーザーベースに最高の体験を提供するために、定期的にフィーチャーフラグを利用しています。これらの組織は何千ものフラグを持っており、スケールに合った運用を確保するために、適切に衛生管理することが必須となります。
しかし、バックログを作成し、ソフトウェアデリバリープロセスを加速するにつれ、フラグ地獄が忍び寄ってくる可能性があります。規模が拡大したときにフラグをどのように管理するかを考えることは重要ですが、事前に計画を立てることは有益なことです。
フィーチャーフラグをデフォルトで使う
"フィーチャーフラグを立てるのはいいけれど、どうやって始めればいいの?"
これは私たちがいつも受ける質問で、その通りだと思います。しかし、私たちの答えはいつも同じです。あなたが行おうとしているあらゆるコードの変更を、フィーチャーフラグの後に置くのです。
ある機能に対してフラグをどう使うか、あるいは何を制御したいのか、適切なユースケースが出てくるのを待つのではなく、変更を加えるならCDを通すべきというのと同じ意味で、フィーチャーフラグをCDのパイプラインのように考えてみてください。つまり、もし変更を加えるなら、それをフラグの後に置くべきでしょう。
フィーチャーフラグは、今後のテストプロセスの中核となるべきもので、フラグの背後にある変更が多ければ多いほど、将来的にオプションが増えることになります。ある変更がシステムダウンを引き起こす場合、フラグを立てておけば、そのような使用例を事前に想定していなかったとしても、それをオフにできます。同様に、任意の環境で変更をテストし、データを収集できるということは、今すぐには予定していなくても、いつでも役立つ可能性があります。多くのフィーチャーフラグは個別の機能を包含しているので、複数の機能トグルを設定した場合でも、フィーチャーフラグの組み合わせを簡単にオフにすることができます。
トランクベース開発の検討
トランクベース開発とフィーチャーフラグについて、より詳しく書きましたが、この話は改めて説明する価値があります。
トランクベース開発により、チームはより素早く動き、コード展開と機能リリースプロセスから複雑さとリスクを取り除けます。長期間のブランチやコードパスの数を減らし、本番環境でも変更を保持するフィーチャーフラグを増やすことで、より多くのマージ、より多くのデプロイ、そして最終的にはリスクの大幅な削減が可能になります。
(リリーストグルだけではなく)オペレーショナルトグルを考える
その名の通り、フィーチャーフラグはリリーストグルや実験トグルを実現する方法として実装されることがほとんどです。しかし、それ以外にも便利なトグルがあります。重要なのは、フィーチャーフラグを使用して運用トグル(またはopsトグル)を作成することは、フィーチャーフラグの素晴らしい、あまり活用されていない利用法だということです。
機能ではなく、主要な構成設定を制御する特定のコードパスにフラグを設定することで、どのような種類の生産障害にも即座に対応できるようになり、平均解決時間(MTTR)を短縮し、ストレスの多いシステム停止への対応の難しさを軽減することができるのです。
1つのフラグに全てを制御させない
例えば、プレミアムユーザー全員に新機能を展開する場合、この機能にはフロントエンドとバックエンドの両方の変更が必要だとします。これはよくあることです。ユーザー向けの機能のほとんどは、複数の関連した変更が必要になります。これらの変更を全て1つのトグルの背後に置けば合理的に見えるかもしれません。
しかし、実際には、トグルの範囲を小さくして、より小さなフィーチャーフラグをリンクさせる方がよいのです。全てを1つのフラグで管理すると、どのコードパスで問題が発生したのかが分かりにくくなります。さらに、機能を反復する過程で、より個別な変更をテストすることも難しくなります。
防御の最前線としてフィーチャーフラグを活用する
フィーチャーフラグは、コントロールできる最底辺を機能レベル、またはリリースレベルに移動します。デプロイメントをリリースから切り離すことで、エンジニアリングチームは、製品管理、営業、マーケティング、カスタマーサポートなど、それぞれの目的で他のチームがフィーチャーフラグに関与する権限を与えることができるようになります。
これにより、まず、インシデント管理、つまり平均解決時間(MTTR)を改善できます。問題が発生した場合、適切なフィーチャーフラグにアクセスできる人なら誰でも、影響を受けるユーザーやターゲットに対してフラグをオフにするだけでよいのです。エンジニアリングからの正式なエスカレーション対応を待つ代わりに、機能をオフにするこ��とで、障害の影響範囲を最小限に抑え、顧客への影響というプレッシャーを感じずにエンジニアリングが問題を解決できるのです。
もう一つの利点は、ロールバックやロールフォワードの手順を踏まずに問題を解決できることです。一度のデプロイメントに数十から数百の変更があり、個々のエラーのために配備全体をロールバックしなければならないというシナリオを想像してみてください。これは、ソフトウェアデリバリープロセスのデプロイメントフェーズに多大なストレスとプレッシャーを与えることになります。フィーチャーフラグの世界では、ロールバックはありません。オフにすればよいだけです。
そして、デプロイメントが時間とともに大きくなり、デプロイメントにかかる時間が長くなり、よりリスクが高くなるという問題を軽減できます。チームは、インシデントが発生しないように細部まで検証するのに時間をかけなければならず、対策チームの組成やロールバックを始める必要がありません。このプレッシャーを機能レベルに移すことで、デプロイメントがすぐ小さくなり、変更の可能性をフラグで包んでおくことで第二の防御層を追加することができるのです。
本番環境でのライブデータでのテスト
本番でのテストについては、ブログで詳しく書いています。
本番環境でのテストというのは、ちょっと実態と違うような気がします。私たちは、適切なCI/CDプロセスを経ずに機能を本番環境に押し込むことを推奨しているわけではありませんが、チームはテストデータだけでなく、現実の状況下で機能をテストするべきだと考えています。
チームは、本番稼働が可能なフィーチャーフラグを本番環境に置き、その挙動を理解するためにデータを収集できます。「それが問題を引き起こしているか?」、「それは顧客の問題を解決しているか?」、「正しいメトリクスを表示しているか?」といったデータに基づいて、チームは変更やその他の機能に対してより速く反復をし、より質の高い最終成果を提供できます。
また、複数のソリューションを実際の顧客と一緒に試すことも、この応用例の一つです。密室でリスクの高い決断を下し、ベストを尽くすのではなく、チームは複数のMVPを本番稼働させ、何が顧客のニーズを最も満たしているかを確認できるようになります。最終的に、顧客はより多くのものを手に入れ、社内チームはストレスとリスク要因を軽減できます。これはWin-Winの関係です。
ここで重要なのは、本番環境で効果的にテストを行うには、テストから得られた評価データを確実に取得し、それを適切な文脈で適用する必要があるということです。もしフィーチャーフラグを立ててもデータを収集できないなら、本番環境でのテストが可能にする分析をどう行うのでしょうか?
また、そのデータを、収益への影響、ダウンタイムの削減、顧客満足度など、適切なビジネスコンテキストに対応させることも困難です。評価データを取得し、必要な方法で適用できるようにしたいと思うことでしょう。
強制力のあるガバナンスプロセスの構築
フィーチャーフラグ地獄を回避する方法の1つは、優れたガバナンスプロセスを持つことです。ガバナンスとは、基本的に手順とベストプラクティスが守られ、実施されることを保証するためのスケーラブルなプロセスを構築することです。
このガバナンスのステップには、一連の承認を経て、特定のトリガーが満たされたときのみリリースをコミットする、あるいはパフォーマンスメトリクスと照らし合わせて検証する、などが含まれることがあります。ここで重要なのは、機能がリリースされる(デプロイされるのではなく、リリースされる)前に、いくつかのチェックアンドバランスを経て、物事が正しい方法で行われていることを確認し、問題を未然に防ぐ必要があるということです。
一方、問題が発生した場合、それに対してどのように対処するのでしょうか。ガバナンスプロセスの一環として、チームが適切に監査できるようにすることが重要です。特に、フィーチャーフラグのように、個々の変更を独自の管理ポイントに分けるような場合は、問題のトリアージ中に何が起こっているのか、何が起こったのかを理解できるようにすることが非常に重要です。監査ログがすぐに利用できるようにすることは、パズルの1つですが、監査ログに記録されるような手順を踏んだ確固たるガバナンスプロセスを確立することは、おそらくもっと大きなパズルでしょう。
もちろん、これを何らかの方法で自動化できれば、とても素晴らしいことです。プロセスをテンプレート化していき、最終的に自動化する方法も考えてみる価値はあるでしょう。

リリースパイプラインの一部として、ガバナンスを強化した例です。
結論
フィーチャーフラグは、チームをスピードアップし、インシデントの量と程度を軽減し、顧客対応と学習重視の組織をかつてないほど容易に構築することが可能であり、また可能にします。
適切なツール、プラクティス、プロセスを導入することで、フィーチャーフラグを最大限に活用し、その価値を最大限に引き出すことができます。これらのフィーチャーフラグのベストプラクティスによって、順風満帆にフラグを活用する方法が見つかることを期待します。
これらのベストプラクティスを実装し、その能力をサポートするソリューションを確保する方法をお探しなら、HarnessのFeature Flagsをチェックする価値は十分にあると思います。準備ができましたら、デモまたは無料トライアルにご登録ください。それでは、よいコーディングを。
この記事はHarness社のウェブサイトで公開されているものをDigital Stacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。